Amazon Kinesis
This is not an exhaustive documentation of all the existing AWS Services. These are summarized notes that I used for the AWS Certifications.
To see the complete documentation, please go to: AWS documentation
Overview
It is a big data stream tool, which allows to stream application logs, metrics, IoT data, click streams, etc.
-
Kinesis is a managed alternative to Apache Kafka
-
Compatible with many streaming frameworks (Spark, NiFi, etc.)
-
Data is automatically replicated to 3 AZ
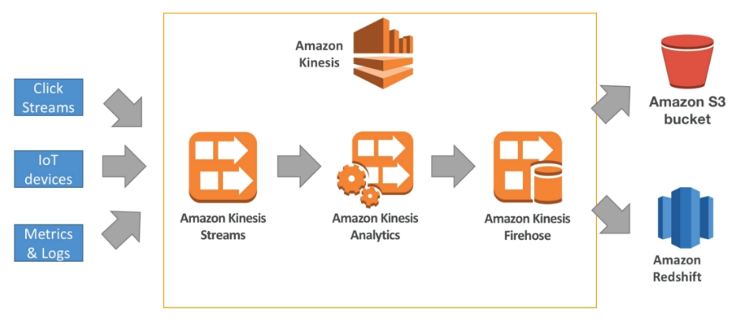
Kinesis offers 3 types of products:
- Kinesis Streams: Low latency streaming ingest at scale
- Kinesis Analytics: Perform real-time analytics on streams using SQL
- Kinesis Firehose: Load streams into S3, Redshift, ElasticSearch
Kinesis Streams
Features:
- Streams are divided in ordered Shards/Partitions.
- For higher throughput we can increase the size of the shards.
- Data retention is 1 day by default, can go up to 365 days.
- Kinesis Streams provides the ability to reprocess/replay the data.
- Multiple applications can consume the same stream, this enables real-time processing with scale of throughput.
- Kinesis is not a database, once the data is inserted, it can not be deleted.
Kinesis Stream Shards
-
One stream is made of many different shards.
-
1MB/sor 1000 messages at write PER SHARD. -
2MB/sread PER SHARD. -
Billing is done per shard provisioned, we can have as many shards as we want as long as we accept the cost.
-
Ability to batch the messages per calls.
-
The number of shards can evolve over time (reshard/merge).
-
Records are ordered per shard!

Kinesis Firehose
- Fully managed service, no administration required, provides automatic scaling, it is basically serverless.
- Used for load data into Redshift, S3, ElasticSearch and Splunk.
- It is Near Real Time: 60 seconds latency minimum for non full batches or minimum 32 MB of data at a time.
- Supports many data formats, conversions, transformation and compression.
- Pay for the amount of data going through Firehose.
Kinesis Data Streams vs. Firehose
-
Streams:
- Requires to write custom code (producer/consumer).
- Real time (around 200 ms).
- Must manage scaling (shard splitting / merging).
- Can store data into stream, data can be stored from 1 to 7 days.
- Data can be read by multiple consumers.
-
Firehose:
- Fully managed, sends data to S3, Redshift, Splunk, ElasticSearch.
- Serverless, data transformation can be done with Lambda.
- Near real time.
- Scales automatically.
- It provides no data storage.
Kinesis Data Analytics
- Can take data from Kinesis Data Streams and Kinesis Firehose and perform some queries on it.
- It can perform real-time analytics using SQL.
- Kinesis Data Analytics properties:
- Automatically scales
- Managed: no servers to provision
- Continuous: analytics are done in real time
- Pricing: pay per consumption rate
- It can create streams out of real-time queries.
AWS Kinesis API
Put Records
-
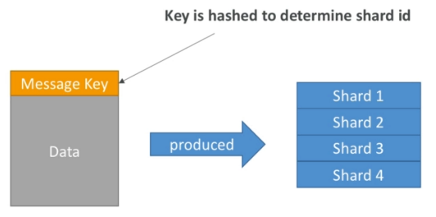
Data must be sent form the PutRecords API to a partition key.
-
Data with the same key goes to the same partition (helps with ordering for a specific key).
-
Messages sent get a sequence number.
-
Partition key must be highly distributed in order to avoid hot partitions.
-
In order to reduce costs, we can use batching with PutRecords API.
-
It the limits are reached, we get a ProvisionedThroughputException.
Exceptions
- ProvisionedThroughputException Exceptions:
- Happens when the data value exceeds the limit exposed by the shard.
- In order to avoid the, we have to make sure we don't have hot partitions.
- Solutions:
- Retry with back-off.
- Increase shards (scaling).
- Ensure the partition key is good.
Consumers
-
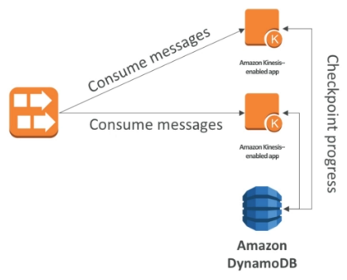
Consumers can use CLI or SDK, or the Kinesis Client Library (in Java, Node, Python, Ruby, .Net).
-
Kinesis Client Library (KCL) uses DynamoDB to checkpoint offsets.
-
KCL uses DynamoDB to track other workers and share work amongst shards.
AWS Kinesis CLI
Sending data:
aws kinesis help
aws kinesis list-streams help
aws kinesis list-streams
aws kinesis describe-streams help
aws kinesis describe-streams --stream-name <name>
## example
aws kinesis put-record --stream-name eden-stream-1 --data "Hello world. Please sign up." --partition-key user_123
aws kinesis put-record --stream-name eden-stream-1 --data "User has sign up." --partition-key user_123
aws kinesis put-record --stream-name eden-stream-1 --data "Registration complete." --partition-key user_123
Retrieving records:
aws kinesis help
aws kinesis get-shard-iterator help

Retrieves a shard iterator for a specified shard:
aws kinesis get-shard-iterator --stream-name <name> --shard-id <shard id> --shard-iterator-type TRIM_HORIZON

Displays usage instructions, options, and examples:
aws kinesis get-records help

Security
- Control access/authorization using IAM policies.
- Encryption in flight using HTTPS endpoints.
- Encryption at rest using KMS.
- Possibility to encrypt/decrypt data client side.
- VPC Endpoints available for Kinesis to be access within VPCs.
Ordering data into Kinesis
- Data with the same partition key goes to the same shard.
- Data is ordered per shard.
Ordering data into SQS