EC2 stuck in "Initializing"
Encountered after Stratis lab
After manually mounting a stratis pool, I unmount it to try to mount it persistenty by adding its entry to fstab. However after I reboot, the EC2 instance gets stuck to 'initializing'.

I tried to stop and start the instance through the console. It now returned a '1/2 checks passed'.
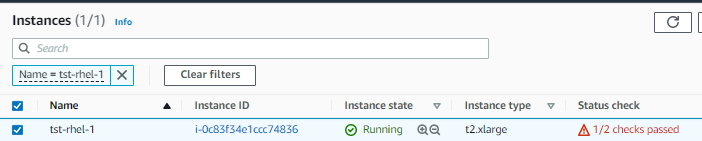
After some searching, I found this two online:
Checked system logs,
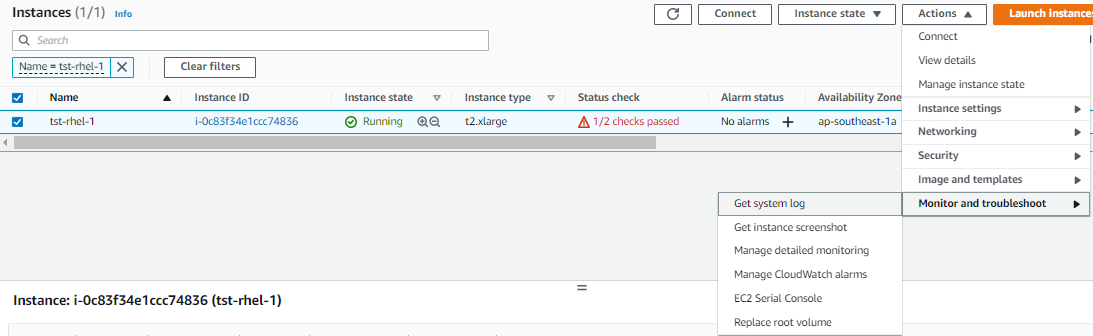
Nothing on it seems to show what caused the issue. Also searched specifically for 'xvd' to show all lines pertaining to the block devices but I don't seem to see anything wrong.
Launched a 2nd EC2 and attached 1st EC2's block device
I first stopped tst-rhel-1 and launched a new EC2 in the same zone, tst-rhel-a2. I then detached the first EC2's root volume and attached it the second as root. I'll try to check if I can get the second up using tst-rhel-1's volume.
It too return a 1/2 checks passsed. Checked the system logs, and I also don't seem anything wrong with it.

Troubleshooting the correct way
After a day, i came back to the problem and returned the root volume back to the tst-rhel and started again. This time I followed the proper troubleshooting guide: Troubleshoot an unreachable instance
System Logs
I opened the system logs again and search for 'unknown', 'error', and 'invalid'. None seem to reflect the root issue (or maybe I still don't know which line may have been telling me something).
In any case, here's the system logs.
[ 1.453285] Freeing initrd memory: 68360K
[ 1.478357] Initialise system trusted keyrings
[ 1.491708] Key type blacklist registered
[ 1.497091] workingset: timestamp_bits=36 max_order=18 bucket_order=0
Give root password for maintenance
(or press Control-D to continue):
Instance screenshot
The next one I saw was taking a screenshot of the instance while it was booting.
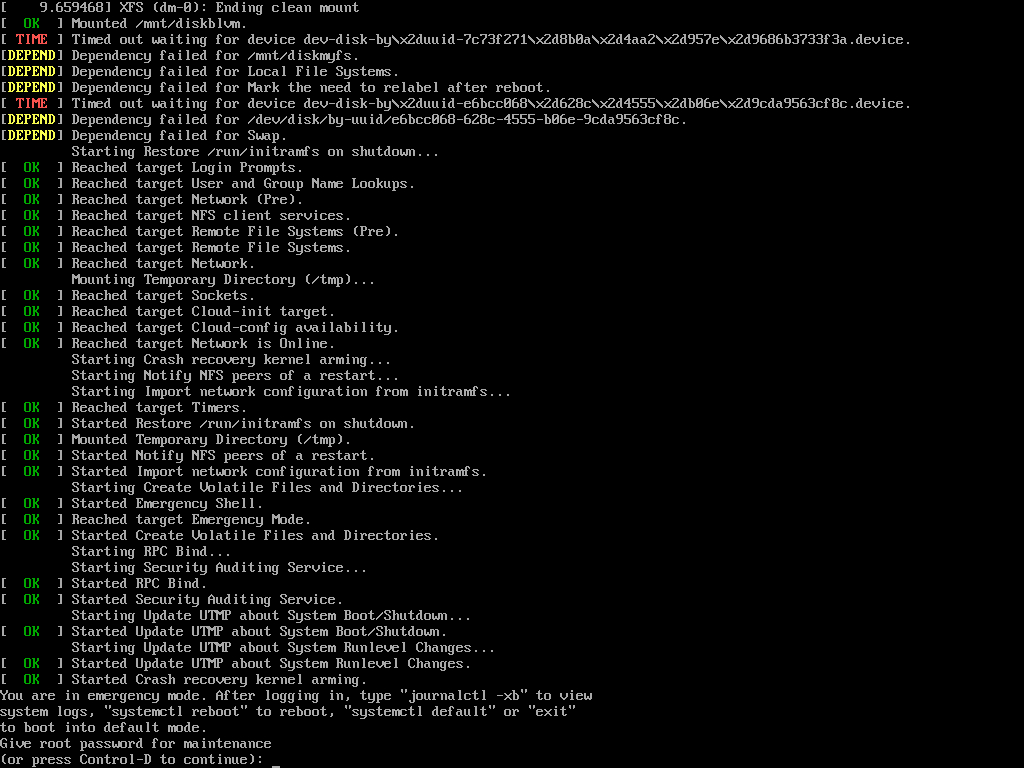
The lines that caught my eye was these:

After some searching, I found this: Timed out waiting for device dev-disk-by\x2duuid-C829\x2dC4C1.device
Which showed almost the exact same lines,
[ TIME ] Timed out waiting for device dev-disk-by\x2duuid-C829\x2dC4C1.device.
[DEPEND] Dependency failed for file system check on /dev/disk/by-uuid/C829-C4C1.
[DEPEND] Dependency failed for /boot/efi.
[DEPEND] Dependency failed for Local File System.
From the same link,
As a filesystem with the old UUID no longer exists udev fails to find it and you get this error. Update the UUID in /etc/fstab using blkid and your system will manage to correctly boot again as this error will be gone.
Launched a new instance and attached the bad host's root volume
Launch a new instance for the second time around and attached the bad host's root volume but this time, I attached it as a secondary volume to the new instance.
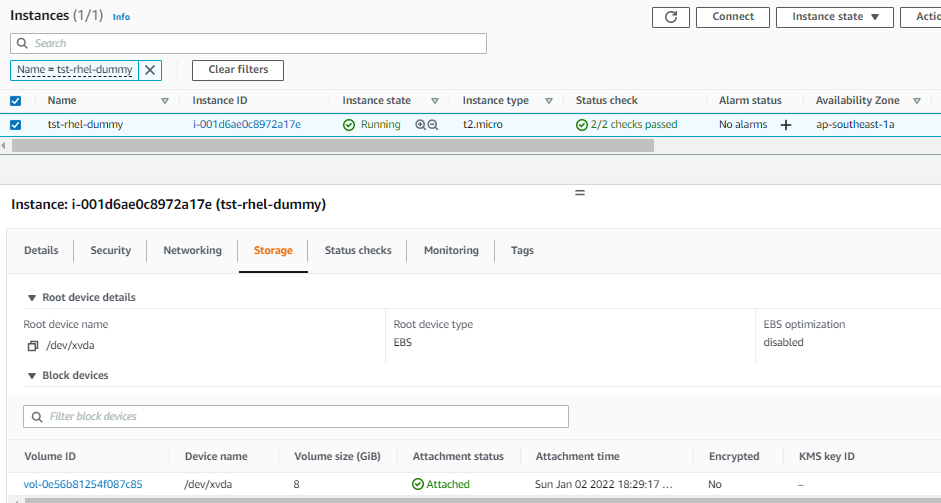
Using /dev/sdx as device name:
Both EBS showing "Attached" and no issues.
Created a mount point and mounted the added block device
[ec2-user@ip-172-31-47-163 ~]$ sudo su
[root@ip-172-31-47-163 ec2-user]#
[root@ip-172-31-47-163 ec2-user]# ll /mnt/
total 0
[root@ip-172-31-47-163 ec2-user]# mkdir /mnt/dummy
[root@ip-172-31-47-163 ec2-user]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdx 202:5888 0 50G 0 disk
├─xvdx1 202:5889 0 1M 0 part
└─xvdx2 202:5890 0 50G 0 part
[root@ip-172-31-47-163 ec2-user]# mount /dev/xvdx2 /mnt/dummy/
[root@ip-172-31-47-163 ec2-user]# ll /mnt/
total 0
dr-xr-xr-x. 18 root root 251 Dec 10 13:05 dummy
[root@ip-172-31-47-163 ec2-user]# ll /mnt/dummy/etc/fstab
-rw-r--r--. 1 root root 959 Dec 31 14:09 /mnt/dummy/etc/fstab
I proceeded to editing the /etc/fstab in the dummy directory. Commented out the line for Stratis.
[root@ip-172-31-47-163 ec2-user]# vim /mnt/dummy/etc/fstab
#
# /etc/fstab
# Created by anaconda on Tue May 4 17:21:38 2021
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
UUID=d35fe619-1d06-4ace-9fe3-169baad3e421 / xfs defaults 0 0
UUID=e6bcc068-628c-4555-b06e-9cda9563cf8c swap swap defaults 0 0
# SWAP
/dev/xvdb2 swap swap defaults 0 0
# LVM
/dev/vgdata/lvdata /mnt/diskblvm xfs defaults 0 0
# STRATIS
# UUID="7c73f271-8b0a-4aa2-957e-9686b3733f3a" /mnt/diskmyfs xfs defaults 0 0
After this I unmounted the volume again and attached it back to the bad host.
[root@ip-172-31-47-163 ec2-user]# umount /mnt/dummy/
[root@ip-172-31-47-163 ec2-user]# ll /mnt/
total 0
drwxr-xr-x 2 root root 6 Jan 2 10:38 dummy
Attached volume back to the bad host
Attached the volume back to the bad host as /dev/sda1
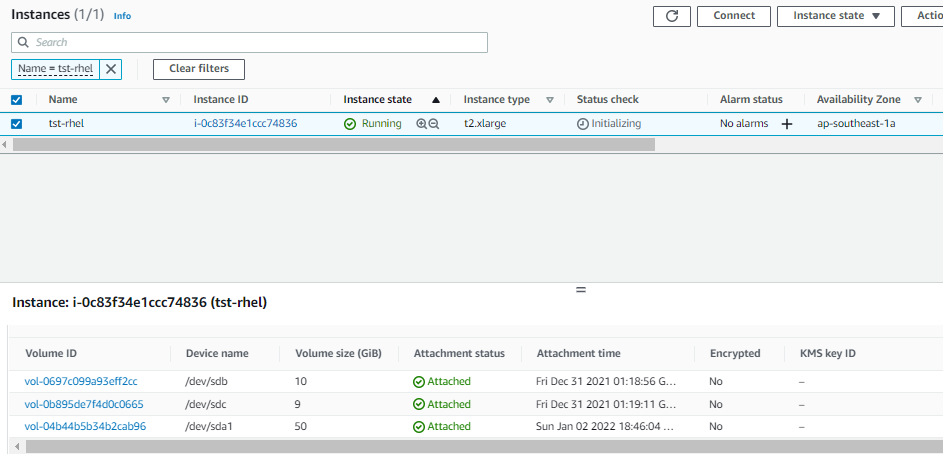
While waiting for it to boot up, I monitored the instance screenshot again. It looked promising because it showed the login stage!
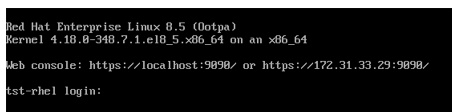
And finally!

EDIT: This actually didn't worked. There was nothign wrong with what I added in /etc/fstab. I tried both the UUID and the '/dev' path but they both returned the same error.
Slow boot: "a start job is running for dev-disk-by..."
After hours spent trying stuff and searching online, I found the solution that worked: Slow boot - "a start job is running for dev-disk-by..."
From the link:
If you have an external device configured to automount (usually with a nofail option in it), add this to the option to the device: x-systemd.device-timeout=1ms. This sets the wait time of the device to be mounted on boot time to 1ms of the default 90 seconds.
What I did:
$ vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Tue May 4 17:21:38 2021
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
UUID=d35fe619-1d06-4ace-9fe3-169baad3e421 / xfs defaults 0 0
UUID="49e5d8a1-78e5-4fde-ad6d-b5692f697058" /mnt/diskfs xfs nofail,x-systemd.device-timeout=1ms 0 0
I unmounted the block device and rebooted.
$ mount | grep diskfs
/dev/mapper/stratis-1-1f2ae191f25d4715bf14e80448521775-thin-fs-49e5d8a178e54fdead6db5692f697058 on /mnt/diskfs type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=128k,sunit=256,swidth=2048,noquota)
$ umount /mnt/diskfs
$ mount | grep diskfs
$ reboot
While rebooting, I monitored the instance screenshot through the EC2 console. The dependency errors didn't appeared anymore.
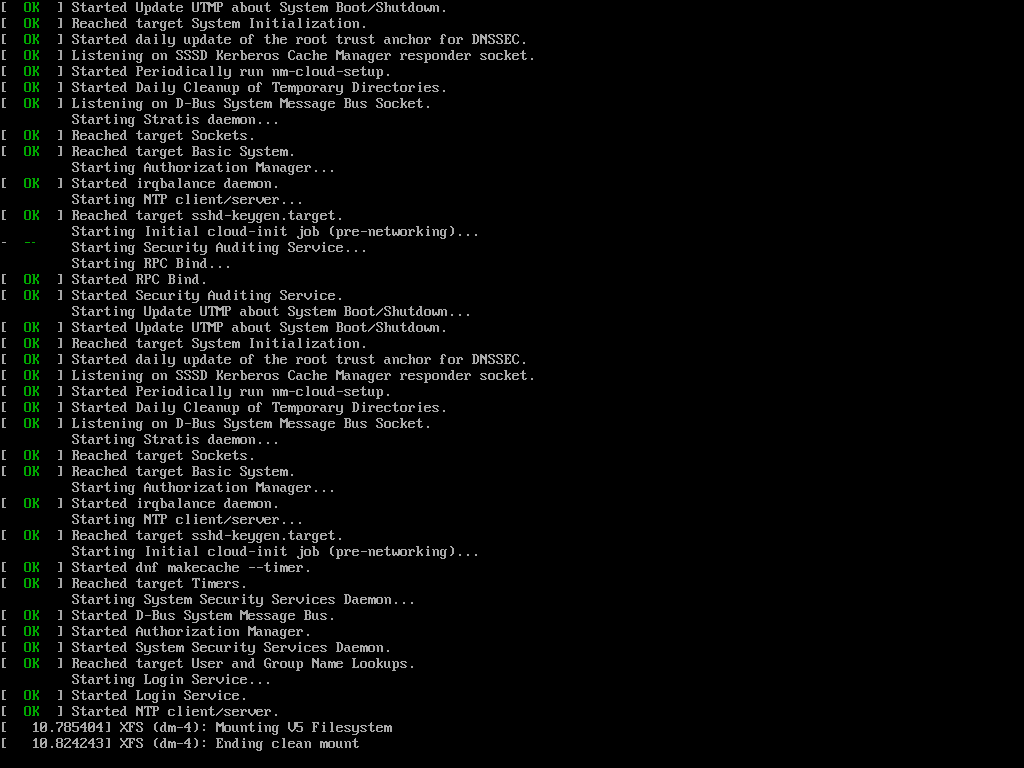
Logged-in to the instance and checked if the stratis pool was mounted,
$ mount | grep diskfs
/dev/mapper/stratis-1-1f2ae191f25d4715bf14e80448521775-thin-fs-49e5d8a178e54fdead6db5692f697058 on /mnt/diskfs type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=128k,sunit=256,swidth=2048,noquota)
Noice!