SPOF and IT Contingency
Single Point of Failure (SPOF) Analysis
Single Points of Failure (SPOF) are critical components in a system that, if they fail, can cause the entire system to stop functioning. Identifying and mitigating SPOFs is essential for ensuring the reliability and availability of systems and services.
-
Identification
- Assess all components and processes within a system.
- Identify elements whose failure would halt system operations.
- Consider hardware, software, network, and human factors.
-
Assessment
- Evaluate the likelihood and impact of each identified SPOF.
- Prioritize SPOFs based on their potential risk to the organization.
- Determine the criticality of each SPOF in the context of business operations.
-
Mitigation
- Implement redundancy for critical components (e.g., backup systems, failover mechanisms).
- Improve reliability of components through maintenance and upgrades.
- Develop and test contingency plans for potential failures.
Steps in Conducting SPOF Analysis
-
Inventory and Mapping
- Create a comprehensive inventory of all system components.
- Map the interdependencies and flow of operations within the system.
-
Risk Assessment
- Identify potential SPOFs in the system
- Analyze the risk associated with each SPOF
- Consider both likelihood and impact
- See Risk Assessments
-
Redundancy Planning
- Design and implement redundancy measures for critical components.
- Use techniques such as load balancing, clustering, and geographical dispersion.
-
Monitoring and Maintenance
- Continuously monitor system performance and health.
- Conduct regular maintenance and updates to ensure reliability.
-
Testing and Validation
- Perform regular testing of failover and backup systems.
- Validate the effectiveness of redundancy measures through simulations and drills.
Example Mitigation Strategies
| Redundancy Type | Description |
|---|---|
| Hardware Redundancy | Use multiple servers, power supplies, and network connections. |
| Software Redundancy | Implement failover software and duplicate critical applications. |
| Network Redundancy | Establish multiple network paths and use load balancers. |
| Human Redundancy | Cross-train staff and document procedures to ensure operational continuity. |
Example Scenario
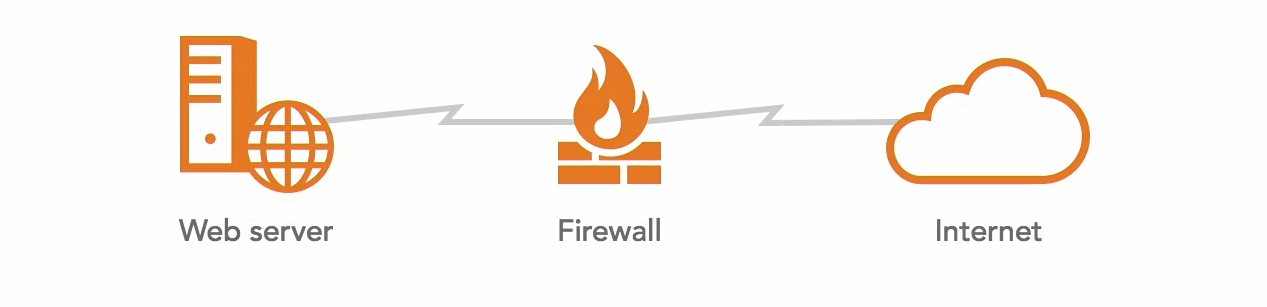
Below is a simple web server architecture that has many single point of failure. Here we have a web server protected by a firewall, which connects to the internet. Each component can be considered a single point of failure since the components are not highly-available.
 |
|---|
To eliminate the points of failure, we can replace the web server with a web server cluster. This ensures that if one server goes down, another server in the cluster can still serve the traffic. In addition to this, we can also replace firewall with a pair of highly-available firewall where one serves as the primary firewall while the other one serves as a backup firewall. Lastly, we can also introduce redundancy to the internal and external connections to ensure that the service continues to operate even if one link fails.
 |
|---|
IT Contingency Plans
IT Contingency Plans are critical for ensuring the continuity of IT services in the face of unexpected disruptions. These plans provide a structured approach to preparing for, responding to, and recovering from incidents that could impact IT operations.
Example Scenarios:
-
Sudden Bankruptcy of a Key Vendor
- Develop alternative supplier arrangements.
- Maintain an inventory of critical vendor dependencies.
- Create contracts with multiple vendors to mitigate risks.
-
Insufficient Compute or Storage Capacity
- Implement scalable cloud solutions to quickly expand capacity.
- Regularly monitor resource usage and plan for growth.
- Maintain a buffer of additional resources to handle unexpected demand.
-
Failure of Utility Service
- Use uninterruptible power supplies (UPS) and backup generators.
- Establish redundant network connections.
- Plan for relocating operations to an alternative site if necessary.
-
Other Risks That May Disrupt IT Operations
- Cybersecurity incidents: Develop incident response plans and conduct regular drills.
- Natural disasters: Create disaster recovery plans that include data backup and off-site storage.
- Human error: Implement robust change management processes and provide regular training.
Having comprehensive IT Contingency Plans ensures that organizations can quickly respond to disruptions, minimizing downtime and maintaining critical operations. These plans should be regularly reviewed and updated to adapt to evolving threats and business needs.
Personnel Succession Planning
Personnel succession planning is a crucial but often overlooked part of business continuity, ensuring key roles are maintained within IT operations.
- IT leadership should work with HR to identify essential team members.
- Plan for potential successors to key roles in case of turnover.
- Provide successors with necessary training and development.
- Ensures continuity when key personnel leave the organization.