Feature Engineering
Overview
After defining a machine learning model, the next step is feature engineering. It is the process of selecting, transforming, and creating variables (features) from raw data to improve model performance.
-
Feature
- A measurable property
- Example: a column in a dataset
-
Raw vs. Engineered Features
- Raw features come directly from data.
- Engineered features are derived or transformed.
Consider a dataset with customer orders.
| Customer ID | Number of Orders | Total Expenditure |
|---|---|---|
| 0 | 11 | $3199 |
| 1 | 5 | $9851 |
| 2 | 9 | $574 |
Where:
- Number of orders: Total purchases by a customer.
- Total expenditure: Total money spent by a customer.
We can create a new feature called Average expenditure which gets the amount paid by the customer per order.
Average Expenditure = Total Expenditure / Number of Orders
| Customer ID | Number of orders | Total expenditure | Average expenditure |
|---|---|---|---|
| 0 | 11 | $3199 | $290.82 |
| 1 | 5 | $9851 | $1970.2 |
| 2 | 9 | $574 | $63.77 |
Types of Feature Engineering
Feature engineering typically involves three main steps:
- Data Aggregation
- Feature Construction
- Feature Transformation
Data Aggregation
Combining data from various sources helps create a richer dataset and improves model accuracy.
- Merge different datasets
- Use varied data types for better insights
In the example below, the DataAggregator class loads data from three sources into a single dataset for further processing:
import pandas as pd
class DataAggregator:
def __init__(self):
pass
def fit(self, data):
pass
def transform(self, data):
data1 = pd.read_csv("data_source1.csv")
data2 = pd.read_csv("data_source2.csv")
data3 = pd.read_csv("data_source3.csv")
# Combine all datasets into one DataFrame
return pd.concat([data1, data2, data3], axis=0)
Feature Construction
Feature construction creates new features from existing ones. This can make the model more interpretable and improve performance.
- Combine or modify existing features
- Work with domain experts to identify relevant features
In the example below, the FeatureConstructor class creates two new features by subtracting the mean of two columns from each value. These new features show how each data point deviates from the mean.
class FeatureConstructor:
def __init__(self):
pass
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
# Find mean of each column
mean_values = X.mean()
# Construct new features by subtracting column means
X['feature1_deviation'] = X['feature1'] - mean_values['feature1']
X['feature2_deviation'] = X['feature2'] - mean_values['feature2']
return X
Feature Transformation
Feature transformation converts data into a format suitable for machine learning models.
- Normalize data for consistency
- Remove outliers to improve model accuracy
- Scale features to ensure they are on the same scale
In the example below, the StandardScaler transformer in scikit-learn scales the features so they have a mean of 0 and a standard deviation of 1. This helps to bring all the data to the same scale, which can improve the performance of certain machine learning models.
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# Load data and split into train/test sets
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Logistic regression model
model = LogisticRegression(random_state=42)
# Without scaling
model.fit(X_train, y_train)
y_pred_no_scaling = model.predict(X_test)
acc_no_scaling = accuracy_score(y_test, y_pred_no_scaling)
# With scaling
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model.fit(X_train_scaled, y_train)
y_pred_with_scaling = model.predict(X_test_scaled)
acc_with_scaling = accuracy_score(y_test, y_pred_with_scaling)
# Output accuracy comparison
print(f"Accuracy without scaling: {acc_no_scaling}") # Example output: 0.971
print(f"Accuracy with scaling: {acc_with_scaling}") # Example output: 0.982
Common Transformation Techniques
Feature transformation is a broad concept that includes various techniques that modify data into a different form to improve model performance. This includes techniques like:
| Technique | Description |
|---|---|
| Normalization | Normalize numeric data to a range of 0 to 1 |
| Standardization | Rescales data to have a mean of 0 and a standard deviation of 1 |
| Log Transformation | Converts skewed data into a more normal distribution |
| Encoding | Converts categorical variables into numerical form |
| Binning | Groups continuous values into discrete bins |
Normalization
Normalization scales numeric features to a range between 0 and 1. This ensures no feature dominates due to its scale.
- Helpful when features have different scales/ranges.
- Useful for models like K-Nearest Neighbors (KNN) and Neural Networks.
We can apply normalization using sklearn.preprocessing.Normalizer. First, we create a normalizer object, then pass the DataFrame to transform the data and return the normalized version.
from sklearn.preprocessing import Normalizer
# Create normalizer object
normalizer = Normalizer()
normalized_data = normalizer.fit_transform(data)
Standardization
Standardization transforms features so they have a mean of 0 and a standard deviation of 1. This is especially useful for models that assume data is normally distributed.
- Standardize data to have mean =
0, std =1. - Essential for models like Support Vector Machines (SVM) and Linear Regression.
We can apply standardization using sklearn.preprocessing.StandardScaler. Similar to normalization, we first create a scaler object, then pass the DataFrame to transform the data and return the standardized version.
from sklearn.preprocessing import StandardScaler
# Create scaler object
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
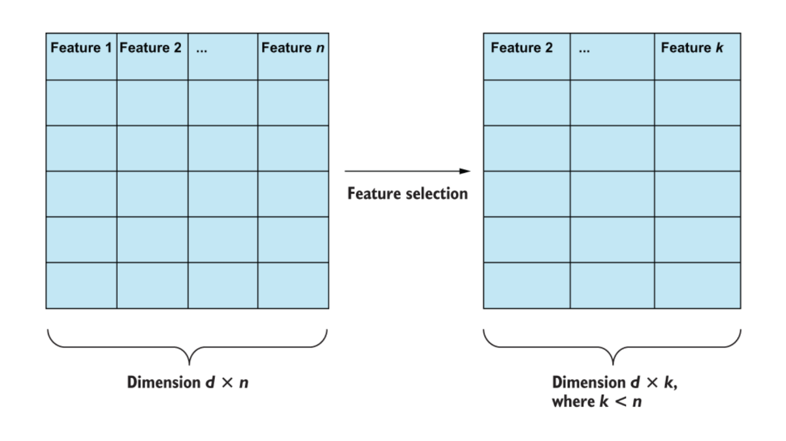
Feature Selection
To improve prediction accuracy, it's crucial to select relevant and non-redundant features. Avoid using features that are too similar or irrelevant.
- Choose features that contribute meaningfully to the model.
- Eliminate redundant or irrelevant features.
Example:
- Age in years is enough
- Avoid adding age in months as it provides the same information.
Note that adding more features doesn’t always help. The goal is to find the most useful ones.
| Technique | Description |
|---|---|
| Feature Selection | Identifying the most important variables |
| Correlation Check | Removing redundant features |
| Dimensionality Reduction | Methods like PCA (Principal Component Analysis) simplify data |
Example: Feature Engineering Pipeline
This pipeline performs a sequence of operations:
- Data aggregation
- Feature construction
- Scaling
- Feature selection
It uses the Chi-squared test to pick the top 10 features. After fitting, the pipeline can transform new data in the same way.
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectKBest, chi2
class FeatureEngineeringPipeline:
def __init__(self):
self.aggregator = DataAggregator()
self.constructor = FeatureConstructor()
self.scaler = StandardScaler()
self.selector = SelectKBest(chi2, k=10)
def fit(self, X, y):
X = self.aggregator.transform(X)
X = self.constructor.transform(X)
X = self.scaler.fit_transform(X)
self.selector.fit(X, y)
def transform(self, X):
X = self.aggregator.transform(X)
X = self.constructor.transform(X)
X = self.scaler.transform(X)
return self.selector.transform(X)
In this code:
fit(): Aggregates, constructs, scales, and selects features for the model.transform(): Applies the same transformations to new data for predictions.
Make sure that DataAggregator and FeatureConstructor are defined and their transform methods work correctly before running this pipeline.
Using sklearn
sklearn.feature_selection helps in selecting the most important features while removing redundant ones. This ensures that the model only uses the most valuable data.
- Use feature selection to identify key predictors.
- Split data to prevent data leakage during feature selection.
In the example below, we first split the data into training and testing sets to prevent data leakage before applying feature selection.
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import train_test_split
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
df_X, df_y, test_size=0.2, random_state=42
)
Using RandomForest
SelectFromModel helps identify important features using a model like RandomForestClassifier. It removes less relevant features to improve efficiency.
- Random Forest ranks feature importance.
SelectFromModelkeeps only the most valuable features.- Reduces model complexity by eliminating irrelevant data.
The parameters optimize performance: n_jobs=-1 uses all CPU cores, while class_weight="balanced" adjusts for imbalanced data, and max_depth=5 limits tree depth.
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
# Train Random Forest
model = RandomForestClassifier(n_jobs=-1, class_weight="balanced", max_depth=5)
model.fit(X_train, y_train)
# Select important features
selector = SelectFromModel(model, prefit=True)
X_selected = selector.transform(X_train)
Choosing the Best Approach
Here are four options ranked in order of effectiveness for improving feature engineering:
-
Consult a domain expert
- Get insights from someone with expertise in the field.
- Helps identify features that are most relevant to the problem.
-
Use a combination of feature selection tools
- Apply techniques like univariate selection, PCA, and Recursive Feature Elimination (RFE).
- Ensures only the most valuable features are kept.
-
Use as many features as possible
- Adds all available features, assuming more data improves performance.
- Can lead to overfitting and unnecessary complexity.
-
Manually create features based on intuition
- Develop new features based on gut feeling.
- Lacks a systematic approach and may not improve the model.
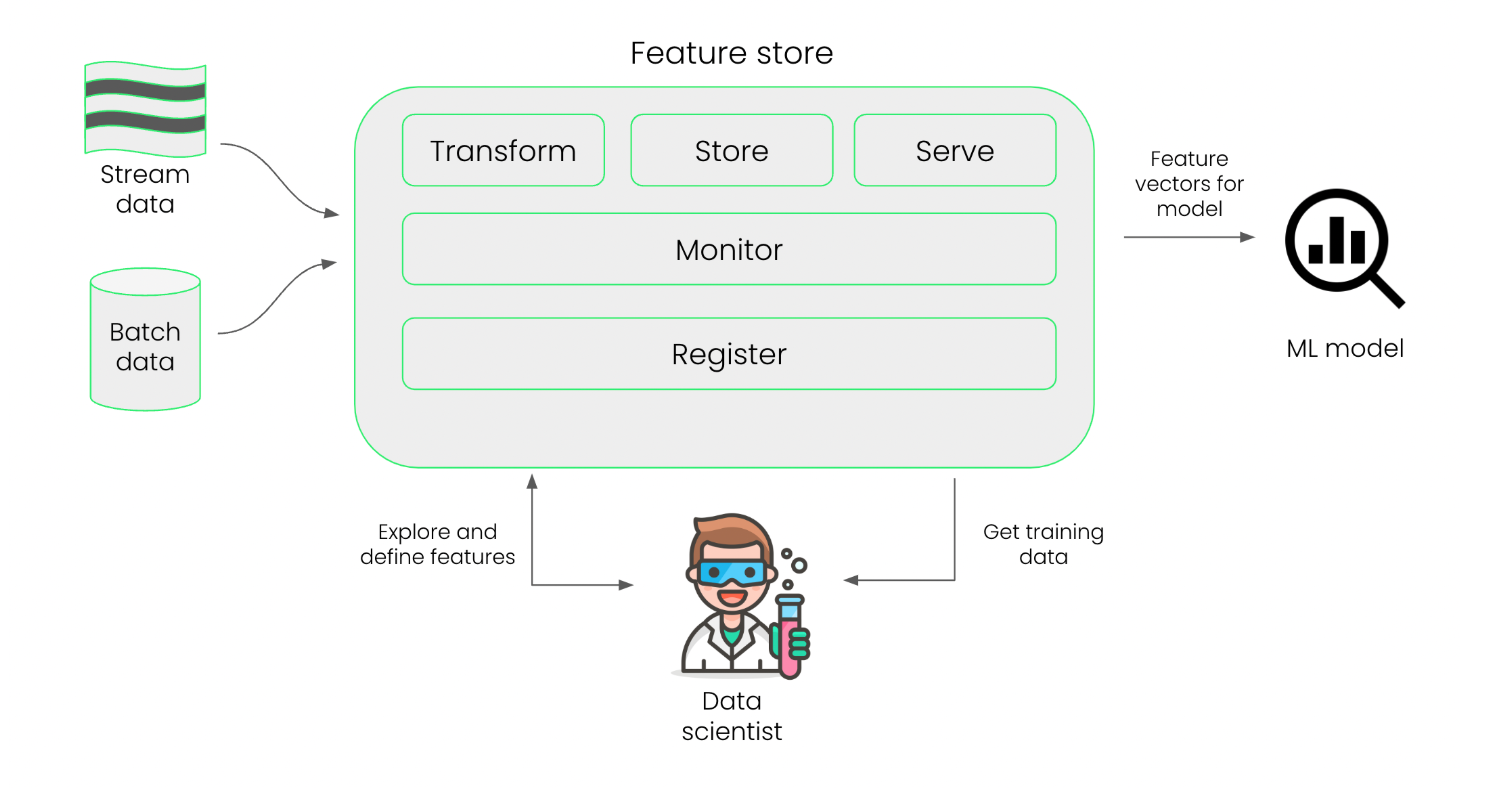
Feature Store
A feature store is a central location to save and reuse features across projects. It helps large teams maintain consistency, but smaller projects may not need it.
For more information, please see Feature Stores.
Data Version Control
Just like Git tracks code changes, data version control tracks dataset changes.
- Keeps history: Allows rolling back to previous versions.
- Ensures consistency: Prevents unexpected changes in model inputs.