Automation within SRE
Benefits of Automation
Automation in Site Reliability Engineering (SRE) offers significant advantages by streamlining operations and enhancing efficiency. By reducing human error and speeding up responses, automation ensures more consistent and reliable service delivery.
- Faster action and fixes
- Time-savings for strategic tasks
- Eliminates repetitive toil
- Improves SLOs
- Enhances overall service delivery
Requirements for Automations
Implementing automation in SRE involves meeting certain prerequisites to ensure success. These include having a well-defined problem to address, choosing suitable tools, dedicating resources for initial setup, and establishing metrics to assess the automation's performance.
- Clear objectives and goals for the automation.
- Integration capabilities with existing systems.
- Skilled personnel to design and maintain the automation.
- Continuous monitoring and evaluation mechanisms.
Characteristics of Good Automation
Effective automation in SRE incorporates several key traits. It should integrate with operations and infrastructure practices, include comprehensive testing, and ensure secure and observable systems.
- Operations-led and using IaaC.
- Automated functional and non-functional testing.
- Canary tests and blue-green deployments.
- Versioned and signed artifacts.
- Enabled instrumentation for observability.
- Performance testing for future growth.
- Clear anti-fragility strategy.
1. Operations-led and using IaaC
Automation effort is "Ops" lead, which means shifting operations at the early stage to ensure reliability engineering opprotunities.
- Environments must be provisioned as Infrastructure as Code (IaaC).
- Apply immutability, environments do not "mutate" but are clean re-builds.
- When change are required, environment need to be re-build.
- This maeks code consistent, repeatable, and productin-ready.
- Easy to test and audit changes.
- Easy to reproduce errors in test environment.
- All codes can be rebuilt from code repositories.
2. Functional and Non-functional Tests
In SRE practices, automation plays a crucial role in ensuring the reliability and stability of systems. This includes conducting a variety of tests across different stages of the development and deployment lifecycle.
-
Functional tests involve simulating real-world scenarios to verify that specific functions of the system behave as expected.
- Using a dummy account to perform transactions in a production-like environment.
- This helps validate the system's functionality under normal operational conditions.
-
Non-functional tests are essential for evaluating system attributes beyond specific behaviors. These tests focus on aspects like performance, scalability, and availability before the application is deployed into production.
- Verifying if the system is running and responsive.
- Ensuring connectivity and network accessibility.
- Assessing the system's capacity to handle expected and unexpected loads.
- Questions asked:
- Is the system running?
- Can I connect?
3. Canary and Blue-Green
Canary testing and blue-green deployments are essential strategies for managing deployments and minimizing risk during software updates. These deployment strategies minimize downtime and reduce disruptions by providing a mechanism to validate changes before they impact a wide audience.
-
Canary Testing involves deploying new code changes to a small subset of users or servers in production before rolling them out to the entire infrastructure.
- Monitor performance and stability of the new version in a controlled environment.
- If issues arise, the deployment can be automatically rolled back to previous version.
-
Blue-Green Deployments maintain two identical production environments, referred to as "blue" and "green."
- Current production environment (blue) continues to serve user traffic.
- New version of the application (green) is deployed and undergoes testing in isolation.
- Tests are conducted to validate the new version's functionality and performance.
- If the tests fail, traffic remains routed to the blue environment.
- If the tests pass, traffic is gradually shifted from blue to the green environment.
4. Versioned and Signed Artifacts
The build step needs to version and digitally sign the comonents that make up the service, and all its components should be securely stored in a suitable artifact repository, such as Artifactory.
- Changes are automated.
- Dependency errors are reduced.
- Easier tod etermine security vulnerabilites.
5. Making Services Observable
Instrumentation like monitoring should be enabled in pre-prod and prod environments to ensure that services are observable from the outside.
- Security and audit events are centralized.
- Reduced mean time to fix since developers have read-only access to log.
- Protective monitoring,to detect and respond to potential threats promptly.
Notes on monitoring:
- Correct data and service-level indicators should be reported by monitoring.
- Monitoring should also return generated and stored log files.
Tools that can make services externally observable:
- Nagios
- Prometheus
- Splunk
- Catchpoint
Tools for aggregating log files for failure analysis:
- Logstash
6. Performance Testing
Performance testing is essential for evaluating how well a service can scale to accommodate anticipated future growth.
-
Auto Scaling:
- Dynamically adjusts to predicted and unexpected demand.
- Minimizes manual intervention and optimizes resource allocation.
-
Reduced Toil:
- Minimizes repetitive manual work in managing and scaling services.
- Achieved through thorough upfront performance testing.
-
Optimized Resource Allocation:
- Improves resource usage efficiency.
- Reduces Total Cost of Ownership (TCO) for service maintenance and scaling.
7. Clear Anti-Fragility Strategy
We can use chaos engineering to test failures and address any discovered failures that may lead to service disruption.
- Ensure a disaster recovery plan (DR Plan) is validated through fire drills.
- Ensure on-call personnel are ready.
When implemented correctly, this strategy ensures:
- Mitigation of availability and integrity risks.
- Risks are reduced as mitigations are evidenced and tested.
Tools to alert and support unplanned incidents:
- PagerDuty
- VictorOps
- Squadcast
Hierarchy of Automation Types
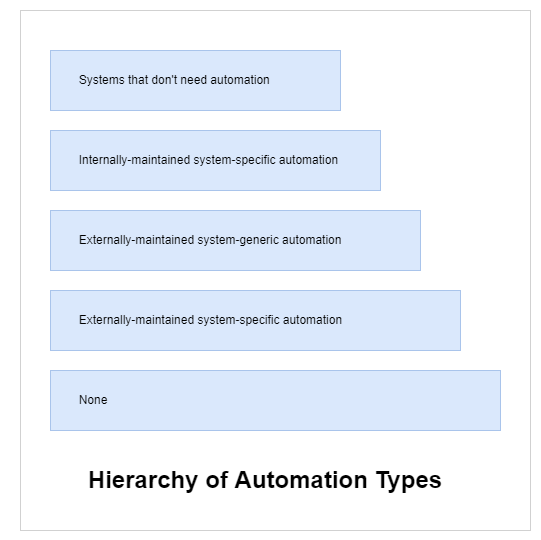
Based on an idea that is originated by Google, the hierarchy of automation types describes automation in different forms.
At the very beginning, there is no automation in place. We can see that automation starts to appear and mature as an organization steps up in the hierarchy. As an example, we could use a simple database and how automation can improve and support:
