Amazon S3
This is not an exhaustive documentation of all the existing AWS Services. These are summarized notes that I used for the AWS Certifications.
To see the complete documentation, please go to: AWS documentation
Overview
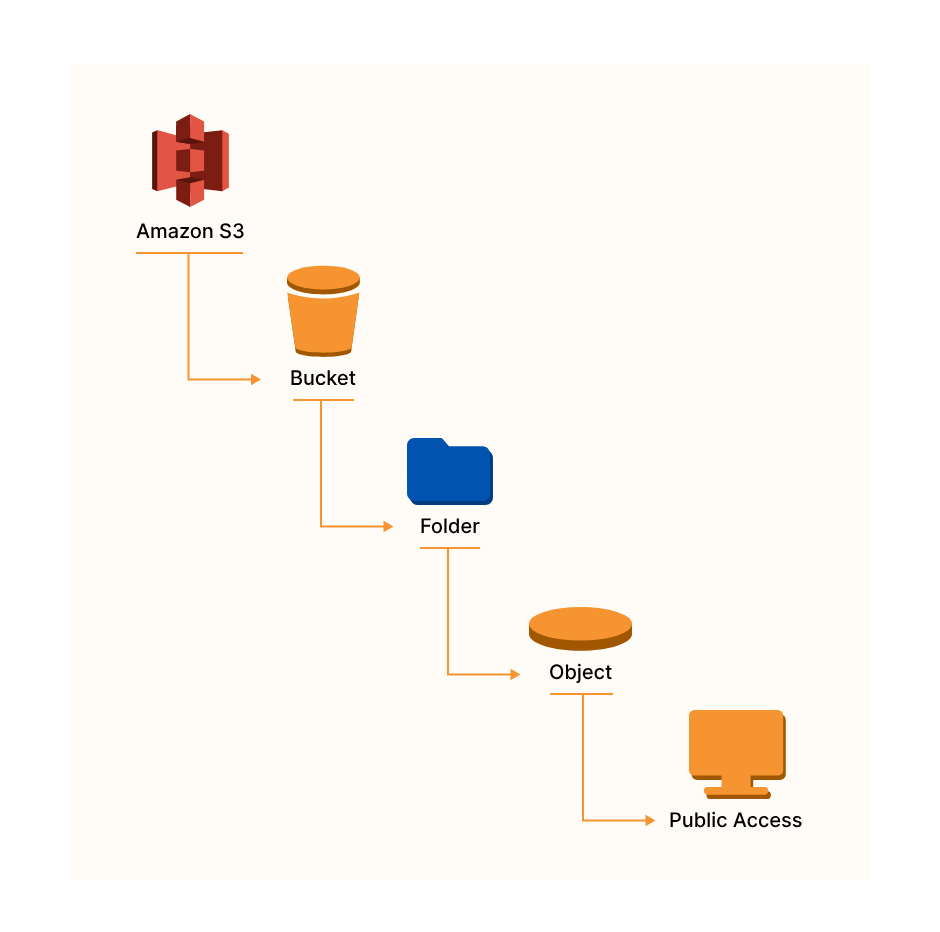
Amazon Simple Storage Service (Amazon S3) is an object storage service built to store and retrieve any amount of data from anywhere.
- Data is stored as objects within “buckets”
- Buckets are defined at the region level
- Buckets must have a globally unique name
- Buckets are private by default
- Only the bucket owner has initial access
In reality, there is no concept of "directories" within buckets because S3 follows a flat structure. However the UI will actually show that you can have directories within directories.
S3 Bucket Naming Convention
- No uppercase
- No underscore
- 3-63 character long names
- Name must no be an IP
- Must start with a lowercase letter or number
S3 Objects
Data is stored as objects within resources called “buckets”
-
An object can be up to 5 terabytes in size.
-
Objects do have a key as an identifier, which is basically the full path of the file:
s3://my-bucket/my_file.txts3://my-bucket/my_folder/another_folder/my_file.txt -
The key is composed of the prefix + object name
s3://my-bucket/my_folder/another_folder/my_file.txt -
Object values are the content of the body:
- Max object size in S3 is 5TB
- In case of a upload bigger than 5GB, we must use multi-part upload
-
Each object can have metadata: list of text key/value pairs - system or user added
-
Each object can have tags: unicode key/value par, useful for security, lifecycle. A bucket can have up to 10 tags
-
If versioning is enabled each object has a version ID
S3 Versioning
When versionining is enabled (at the bucket level),files can have multiple versions.
-
If a files is uploaded with the same key (same filename) the version of the file will be changed, the existing file wont be overridden, we will have both files available with different versions
-
It is best practice to version the files, because:
-
The files will be protected against unintended deletes
-
The files can be rolled back to previous versions
-
Notes:
-
Any file that is not versioned prior to enabling versioning will have the version "null"
-
Suspending versioning does not delete the previous versions of the file
Without Versioning
- Each object is identified solely by the object key, it's name.
- If you modify an object, the original of that object is replaced.
- The attribute, ID of object, is set to null.
Deleting versioned files
- When deleting a versioned file adds a delete marker to the file, but the file wont be deleted
- The file can be restored by deleting the delete marker
- Deleting the delete marker and the file together is a permanent delete, meaning the file wont be able to be restored
MFA Delete
- To use MFA-Delete we have to enable versioning on the selected bucket
- MFA-Delete can be enabled/disabled only by the owner of the bucket (root account)!
- MFA-Delete currently can only be enabled using the CLI
- MFA will be required when:
- We want to permanently delete an object version
- We want to suspend the versioning on the bucket
- MFA won't be required when:
- We want to enable versioning
- We want to list deleted versions
- We want to add a delete marker to an object
S3 Static Hosting
S3 can host static websites and have them accessible from the internet
-
The website URL will be something like this:
<bucket-name>.s3-website-<AWS-region>.amazonaws.com<bucket-name>.s3-website.<AWS-region>.amazonaws.com -
In case of
403errors we have to make sure that the bucket policy allows public reads
Use cases:
- Storing web content
- Storing backups for Relational DB
- Storing logs for analytics
S3 Cross Origin Resource Sharing (CORS)
CORS is a web browser based mechanism to allow requests to other origins while visiting the main one
-
An origin is a scheme (protocol), host (domain) or port
-
Same origin example:
http://example.com/app1http://example.com/app2 -
Different origins:
http://example.comhttp://otherexample.com -
The request wont be fulfilled unless the other origin allows for the request, using CORS headers (example: Access-Control-Allow-Origin, Access-Control-Allow-Method)
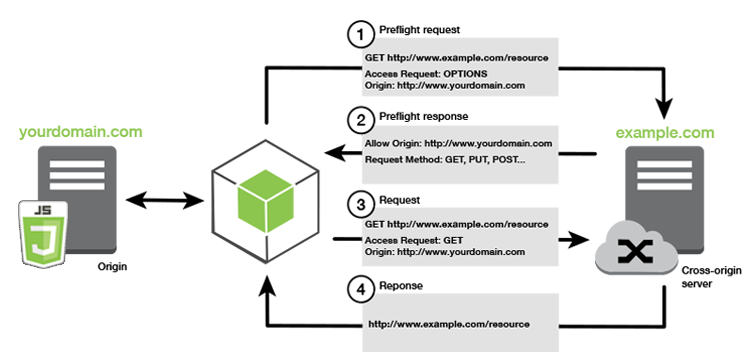
-
If a client does a cross-origin request on an S3 bucket, the correct CORS headers need to be enabled in order for the request to succeed
-
Request can be allowed for a specified origin (by specifying the URL of the origin) or for all origins (by using *)
S3 Consistency Model
Amazon S3 follows two consistency models:
-
Read-after-write consistency for PUTs to new objects (new key).
-
Eventual consistency for GETs and DELETEs of existing objects (existing key).
S3 HTTP Codes
| HTTP Code | Description |
|---|---|
| 200 | Successful upload |
| 300 | Redirection |
| 400 | Client error |
| 500 | Server error |
S3 Access Logs
- For audit purposes we would want to log all access to S3 buckets.
- Any request made to S3, from any account, authorized or denied, will be logged into another S3 bucket.
- The data can be analyzed by some data analysis tools or Amazon Athena.
- We should never set our logging bucket to be the monitored bucket! This may create a logging loop causing the bucket to grow exponentially.
S3 Replication
To enable replication:
- Enable versioning on the source and destination buckets.
- Only the new objects are replicated after the replication is activated (no retroactive replication).
- Buckets can be in separate accounts.
- Copying between replica buckets happens asynchronously (it is very quick).
- In order to be ably to copy between replicas, an IAM permission has to be assigned to the source bucket.
For DELETE operations:
- For deletion without version ID, a delete marker is added to he object. Deletion is not replicated.
- For deletion with version ID, the object is deleted in the source bucket. Deletion is not replicated.
There is no chaining of replication:
- If bucket-A has replication into bucket-B, and bucket-B has replication into bucket-C.
- Then objects created in bucket-A are not replicated to bucket-C.
Types of replication
-
Cross Region Replication (CRR)
- Buckets are in different regions
- Used for: compliance, lower latency access, replication across accounts
-
Same Region Replication (SRR)
- Buckets are in the same region
- Used for: log aggregation, live replication between production and test accounts
S3 Pre-signed URLs
Reference: Sharing objects with presigned URLsBy default, all Amazon S3 objects are private, only the object owner has permission to access them. However, the object owner may share objects with others by creating a presigned URL. A presigned URL uses security credentials to grant time-limited permission to download objects.
- The URL can be entered in a browser or used by a program to download the object.
- The credentials used by the presigned URL are those of the AWS user who generated the URL.
- Users given a pre-signed URL will inherit the permissions of the person who generated the URL.
- We can generate pre-signed URLs using the SDK and the CLI.
- Pre-signed URLs have a default wait time of 3600 seconds. This can be changed with
--expires-inargument.
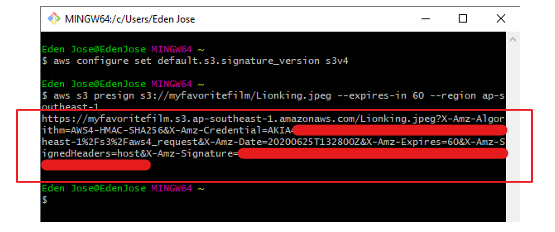
For downloads, we can configure through CLI:
aws s3 presign help
Aaws configure set default.s3.signature_version s3v4
aws s3 presign s3://myfavoritefilm/Lionking.jpg --expires-in 120 --region ap-southeast-1
S3 Lifecycle Policies
We can transition objects between storage classes in order to save money
- Infrequently access documents should be moved to STANDARD_ID.
- Objects that don't need real-time access should be moved to GLACIER or DEEP_ARCHIVE.
- Moving objects can be done manually or can be done via a lifecycle configuration.
- Rules can be applied for a certain prefix.
- Rules can be created for certain object tags.
Transaction Actions
Transaction actions define when should objects be transitioned from one storage to another
- Move objects to Standard IA class 60 days after creation
- Moveto Glacier for archiving after 6 months
Expiration actions
Expiration actions deletes objects after a given time.
- Can be used to delete old versions of files if versioning is enabled on the bucket
- Can be used to clean-up incomplete multi-part uploads
S3 Lock Policies
-
S3 Object Lock
- Implements WORM (Write Once Read Many Model) model, meaning that it guarantees that a file is only written once and it can not be deleted until the lock is removed
-
Glacier Vault Lock
- Same WORM model is implemented, locket file can not be changed as long as the lock is active. Helpful for compliance and data retention
S3 Event Notifications
Amazon S3 Event Notifications can be used to receive notifications when certain events happen in your S3 bucket.
-
To enable notifications, add a notification configuration that identifies the events that you want Amazon S3 to publish.
-
Make sure that it also identifies the destinations where you want Amazon S3 to send the notifications.
-
Store this configuration in the notification subresource that's associated with a bucket.
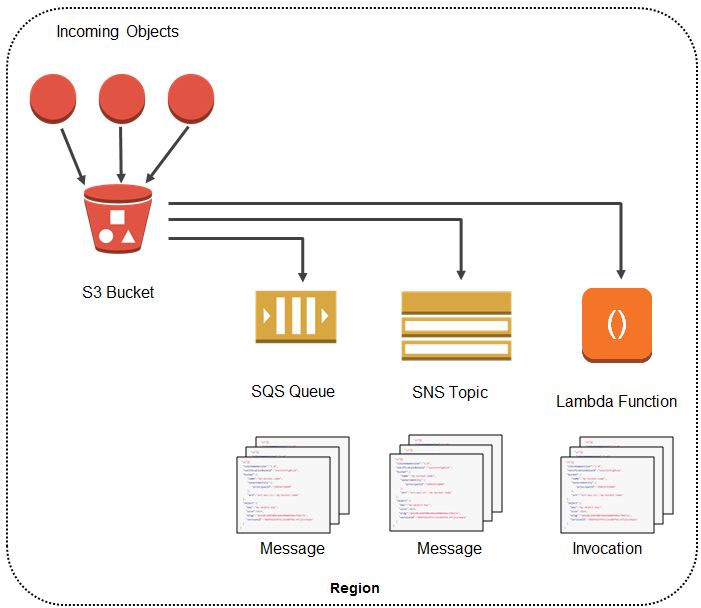
Currently, Amazon S3 can publish notifications for the following events:
- New object created events
- Object removal events
- Restore object events
- Reduced Redundancy Storage (RRS) object lost events
- Replication events
- S3 Lifecycle expiration events
- S3 Lifecycle transition events
- S3 Intelligent-Tiering automatic archival events
- Object tagging events
- Object ACL PUT events
Amazon S3 can send event notification messages to the following destinations.
- Amazon Simple Notification Service (Amazon SNS) topics
- Amazon Simple Queue Service (Amazon SQS) queues
- AWS Lambda function
- Amazon EventBridge
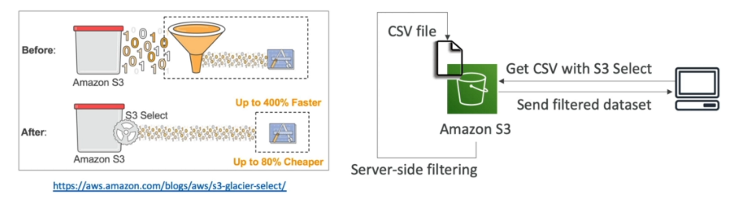
S3 Select and Glacier Select
This provides a ways to retrieve parts of objects and not the entire object.
-
If you retrieve a 5TB object, it takes time and consumes 5TB of data. Filtering at the client side doesn't reduce this cost.
-
S3 and Glacier select lets you use SQL-like statements to select part of the object which is returned in a filtered way.
-
The filtering happens at the S3 service itself saving time and data.
-
We can filter by rows and columns. SQL statements should be simple, we can not have joins
-
The purpose of S3 Select is to use less network traffic