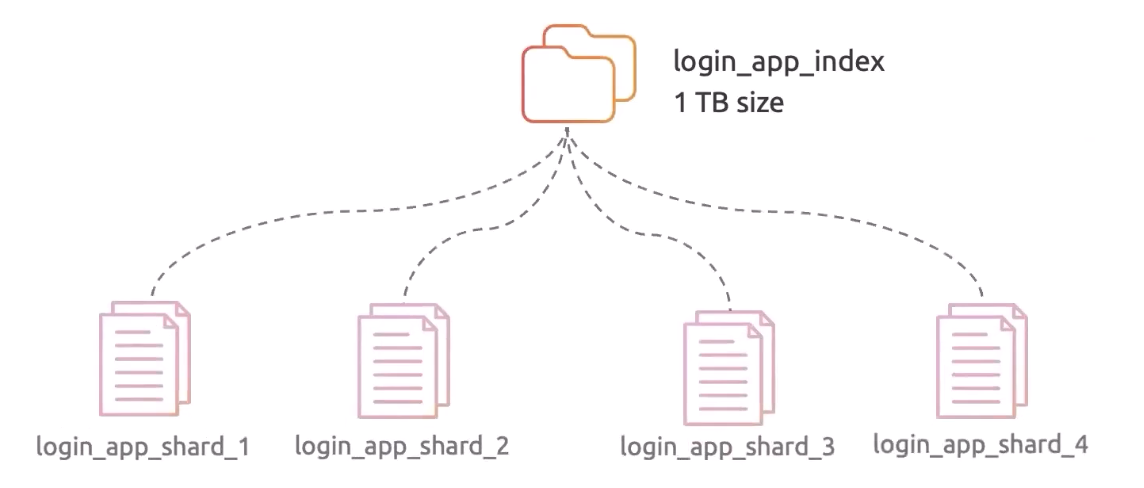
Shards
Overview
Elasticsearch is designed to scale horizontally, which means it can grow by adding more nodes to the cluster. It scales by distributing data across shards which ensures efficient storage and retrieval.
As demand increases, additional nodes can be added to the cluster, and more shards can be created for better scaling.
-
Shards
- Indexes are divided into smaller units called shards.
- Each shard acts as an independent, self-contained index.
- They are distributed across multiple nodes in the cluster.
-
Scalability
- As demand increases, additional nodes can be added to the cluster.
- More shards are created to handle the growing workload effectively.
-
Parallel Processing
- Search and indexing operations can run concurrently .
- This is done distributing data across shards; improves speed and efficiency.
-
Fault Tolerance
- When a node fails, affected shards are relocared to other live nodes
- This maintains system availability and performance.
-
Rebalancing
- Elasticsearch monitors the cluster continuously
- Shards are moved automatically to optimize resource utilization.
- Processing happens across different nodes based on their assigned labels.
-
Shard Sizing
- Larger shards are better for bulk indexing,
- Smaller shards improve flexibility for scaling and rebalancing.
- The right shard size depends on the hardware and specific use case.
Primary and Replica Shards
Elasticsearch uses primary and replica shards to store and balance data.
Primary shards hold the main data, while replica shards provide redundancy and improve read performance in a cluster with multiple nodes.
-
Data Redundancy
- Replicas create multiple copies of your data across different nodes.
- This ensures data availability even if a node fails.
-
High Availability
- Redundant data ensures uninterrupted service
- Keeps your data accessible at all times.
-
Increased Read Capacity
- Read requests are distributed across multiple copies of the data
- Reduces the load on individual nodes and enabling simultaneous query handling.
-
Configurable per Index
- The number of replica shards can be set for each index based on redundancy and performance requirements.
- More replicas improve availability but consume additional storage space.
-
Automatic Shard Allocation
- Elasticsearch automatically assigns shards to nodes in the cluster.
- This ensures optimal resource utilization and load balancing.
-
Shard Recovery
- When a primary shard fails, Elasticsearch promotes a replica shard to primary.
- It then rebalances the cluster to maintain data integrity and continuity.
-
Zero Downtime Scaling
- Elasticsearch allows scaling without downtime.
- New nodes can be added to the cluster, and shards are redistributed seamlessly.
Replica shards cannot allocate to the same node of their primary shard. If both reside in the same node, it completely defeats the purpose of data replication!
In the example below, the cluster has three nodes, each with two shards:
- Node-1: Primary shard (primary-1) and a replica (replica-0).
- Node-2: Two replicas (replica-0 and replica-1).
- Node-3: Primary shard (primary-0) and a replica (replica-1).
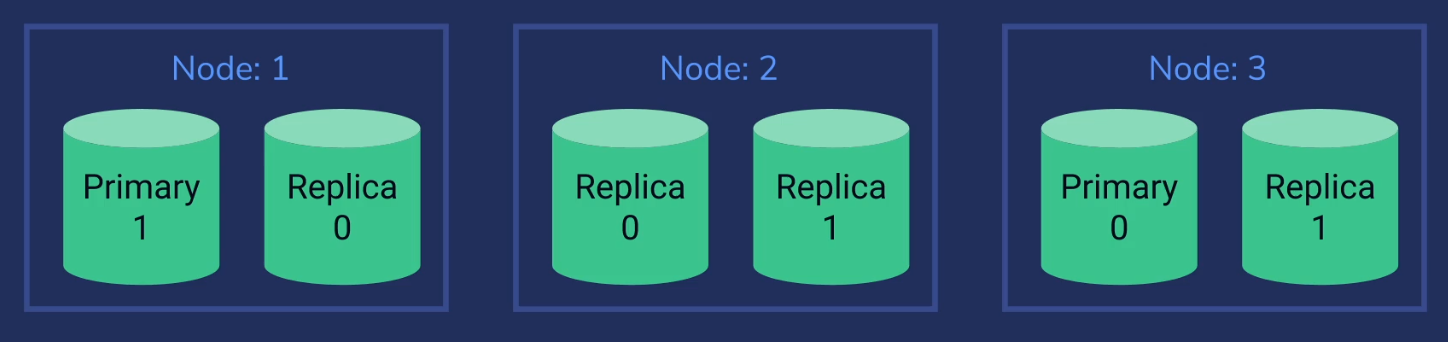
This setup has two primary shards and two replicas:
- Write requests routed to primary shards and replicated to replicas.
- Read requests handled by primary or replica shards to balance load.
If Node-1 goes down, Elasticsearch promotes a replica from Node-2 or Node-3 as the new primary, maintaining availability.
- Odd-numbered nodes (e.g., 3, 5, 7) improve resiliency.
- Requests are distributed round-robin to balance the load.
- More replicas increase read capacity.
- Write capacity is limited by the number of primary shards.
Number of Primary Shards cannot be changed later
The number of primary shards must be set when creating an index. However, you can add read replicas later for more throughput. If necessary, re-indexing is an option.
- Set the number of shards upfront using a PUT request.
- This is configured via Elasticsearch's REST HTTP API.
PUT /indexname
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}