Creating Tables
Overview
Relational databases are great for organizing real-world things like customers and products into tables. Each table focuses on one type of thing, which helps avoid repeating the same information. You can also define how different things relate to each other, like a customer purchasing multiple products or a product being bought by several customers.
- Each table focuses on one type of entity.
- Defines relationships between different entities.
Sample Tables
Here is the schema for the sample World table. This tables we'll be used for the examples in this guide.
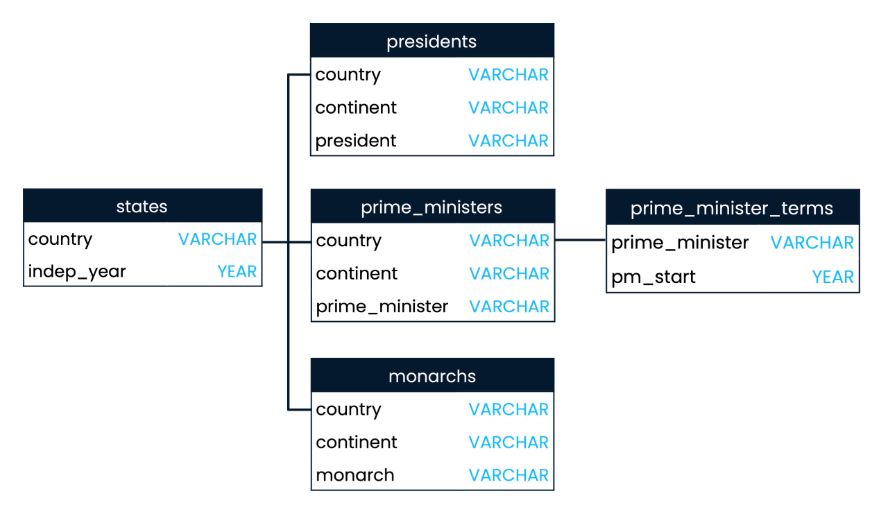
To download the actual files, you can get them from my Github repository:
Building a Database
We can begin with a single table and expand it by adding rules like constraints and keys to keep our data accurate and organized.
- Start small and expand our database.
- Use constraints and keys to keep data accurate.
An example of database is PostgreSQL. To explore a PostgreSQL database, we need to use SQL queries. The information_schema database has lots of useful details about our database’s setup and works in systems like MySQL and SQL Server.
Table Columns
To check out table columns, use the information_schema database. The "columns" table shows you a table’s column details once you know its name, like how the "products" table might hold columns for product name and price.
SELECT table_schema, table_name
FROM information_schema.tables
The output would look something like this. Notice that there's are differnt table schemas here: world, cinema, public, and pg_catalog.
| Table Schema | Table Name |
|---|---|
| world | economies |
| world | languages |
| world | populations |
| world | economies2010 |
| world | countries_plus |
| world | currencies |
| cinema | descriptions |
| public | books |
| pg_catalog | pg_type |
| world | prime_ministers |
| world | states |
To look at tables with specific schemas, use the WHERE command:
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'; -- specify the schema here
To list columns of a specific table (e.g., products):
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'states';
Output:
| Column Name | Data Type |
|---|---|
| name | character varying |
| continent | character varying |
| indep_year | integer |
| fert_rate | real |
| women_parli_perc | real |
Checking the Schema
The command below can be used to check the schema of a given table.
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'add_table_name_here';
Redundancies
In the economies.csv file, you might notice repeated information about economic data and their related attributes.
- Economic data and related attributes are repeated in the same table.
- Indicates redundancy due to mixing different types of data.
For instance, economic metrics such as GDP per capita and inflation rate are stored together, leading to potential redundancy. This can become evident when sorting or querying the data, showing repeated entries for the same country across different years.
We can see this when we sort by year. The output below shows economic data for a specific year but there are many more records in this table.
SELECT * FROM economies
ORDER BY year;
| Econ ID | Code | Year | Income Group | GDP per Capita | Gross Savings | Inflation Rate | Total Investment | Unemployment Rate | Exports | Imports |
|---|---|---|---|---|---|---|---|---|---|---|
| 191 | LBN | 2010 | Upper middle income | 8,755.85 | 3.847 | 3.983 | NULL | NULL | -18.267 | -1.825 |
| 97 | ECU | 2010 | Upper middle income | 4,633.25 | 25.757 | 3.552 | 28.037 | 5.019 | 1.109 | 14.283 |
| 193 | LBR | 2010 | Low income | 341.985 | NULL | 7.291 | NULL | NULL | -0.398 | 10.189 |
| 5 | ALB | 2010 | Upper middle income | 4,098.13 | 20.011 | 3.605 | 31.305 | 14 | 10.645 | -8.013 |
| 195 | LBY | 2010 | Upper middle income | 12,149.59 | NULL | 2.458 | 39.086 | NULL | -0.838 | 9.906 |
| 99 | EGY | 2010 | Lower middle income | 2,921.76 | 19.421 | 11.69 | 21.298 | 9.21 | 3.628 | 11.663 |
| 197 | LCA | 2010 | Upper middle income | 7,491.66 | 11.734 | 3.25 | 28.06 | NULL | 5.423 | 18.427 |
| 51 | BTN | 2010 | Lower middle income | 1,998.75 | 44.674 | 5.726 | 66.906 | 3.3 | -0.579 | 25.991 |
| 199 | LKA | 2010 | Lower middle income | 2,779.74 | 28.457 | 6.218 | 30.352 | 5 | 13.791 | 16.52 |
| 101 | ERI | 2010 | Low income | 395.645 | -9.257 | 11.228 | 9.299 | NULL | 18.085 | 11.854 |
Entity Types
The economies table currently stores various types of economic information in a single table, which may lead to some redundancy. For example, it includes gdp_percapita, gross_savings, and other economic indicators all mixed in one table.
Currently, the database holds different types of data (economic indicators, trade data) in the same table. To reduce redundancy, we can separate these into different tables, ensuring each table focuses on a specific aspect of economic data.
A better approach is to divide the data into separate tables:
-
economic_summary
Column Name Data Type econ_idinteger codecharacter varying yearinteger income_groupcharacter varying -
economic_indicators
Column Name Data Type econ_idinteger gdp_percapitareal gross_savingsreal inflation_ratereal total_investmentreal unemployment_ratereal -
trade_data
Column Name Data Type econ_idinteger exportsreal importsreal
This will help in organizing the data more efficiently and reduce redundancy by storing each type of information in its respective table. The new database model could look like this:
Creating New Tables
The CREATE TABLE command helps define new tables with appropriate columns and data types.
For more information, please see Specifying Types upon Table Creation.
CREATE TABLE table_name (
column_a data_type,
column_b data_type,
column_c data_type
);
To create the three new databases:
CREATE TABLE economic_summary (
econ_id integer,
code character varying,
year integer,
income_group character varying
);
SELECT * FROM economic_summary;
Output:
| econ_id | code | year | income_group |
|---|---|---|---|
CREATE TABLE economic_indicators (
econ_id integer,
gdp_percapita real,
gross_savings real,
inflation_rate real,
total_investment real,
unemployment_rate real
);
SELECT * FROM economic_indicators;
Output:
| econ_id | gdp_percapita | gross_savings | inflation_rate | total_investment | unemployment_rate |
|---|---|---|---|---|---|
CREATE TABLE trade_data (
econ_id integer,
exports real,
imports real
);
SELECT * FROM trade_data;
Output:
| econ_id | exports | imports |
|---|---|---|
Column operations
-
To add a new column to an existing table:
ALTER TABLE table_nameADD COLUMN column_name data_type; -
To rename columns:
ALTER TABLE table_nameRENAME COLUMN old_name TO new_name; -
To delete columns:
ALTER TABLE table_nameDROP COLUMN column_name;
INSERT INTO
After changing the database structure, the next step is to migrate the records from the old table to the new table. To do this, we use the INSERT_INTO command, followed by the target table. We then use the SELECT DISTINCT command followed by the columns or attributes that we want to migrate over.
INSERT INTO new_table
SELECT DISTINCT
column_1_to_be_moved,
column_2_to_be_moved,
FROM old_table
It should return an output like the one below. The "1892" specify the number of records inserted to the new table.
Output: INSERT 0 1892
Note that if we don't use DISTINCT, duplicate records will be migrated as well.
INSERT INTO new_table
SELECT
column_1_to_be_moved,
column_2_to_be_moved,
FROM old_table
Output: INSERT 0 2105
The other way to write is by inserting manually. You can insert new columns as well as new values for those columns.
INSERT INTO new_table (column_a, column_b)
VALUES ("values_a", "values_b",)
DROP TABLE
Note before dropping any table:
- Ensure you have a recent backup of the table data.
- Verify if the table is referenced by other tables (foreign key constraints).
- Verify if the table is used in views, stored procedures, or functions.
- Confirm you have the necessary permissions to drop the table.
- Double-check the table to ensure you are dropping the correct one.
- Inform team members or stakeholders about the table drop.
- Document the reason for dropping the table and the steps to be taken.
- If possible, test the drop command in a development or staging environment.
To drop tables and its data, use the command below.
DROP TABLE table_name;
Note that it will return an error if the table doesn't exist.
table "table_name" does not exist
Use this command instead to drop table if it already exists.
DROP TABLE IF EXISTS table_name;