Data Versioning
Overview
Machine learning projects change often because datasets, features, and models continue to evolve. Data versioning helps teams reproduce experiments and collaborate more effectively.
- Track dataset and model changes
- Reproduce model training results
- Compare performance across experiments
- Monitor changes that require retraining
- Roll back to older versions when needed
- Maintain traceability across projects
Why Data Versioning Matters
Machine learning experiments depend heavily on both code and datasets. Even small dataset changes can affect model performance. Data versioning helps teams understand exactly which datasets were used during training and testing.
Types of Versioning
Versioning is commonly divided into major and minor changes.
- Major versioning
- Minor versioning
Major Versioning
Major versions represent large or significant changes.
- Adding new features
- Replacing datasets
- Changing preprocessing methods
- Switching model architectures
Example:
Version 2.0
This usually indicates major changes to the workflow or dataset.
Minor Versioning
Minor versions represent smaller updates.
- Bug fixes
- Small data adjustments
- Minor preprocessing updates
- Small feature improvements
Example:
Version 1.1
Minor versioning helps track smaller improvements without indicating major workflow changes.
Versioning Training Data
Datasets can be versioned using labels or identifiers.
Example dataset versions:
| Version | Description |
|---|---|
| Version 1.0 | Initial dataset |
| Version 1.1 | Added data transformations (e.g., scaling) |
| Version 1.2 | Added feature selection (e.g., Chi-squared) |
| Version 2.0 | Major update with new data |
Tracking dataset versions helps maintain consistency across experiments and deployments.
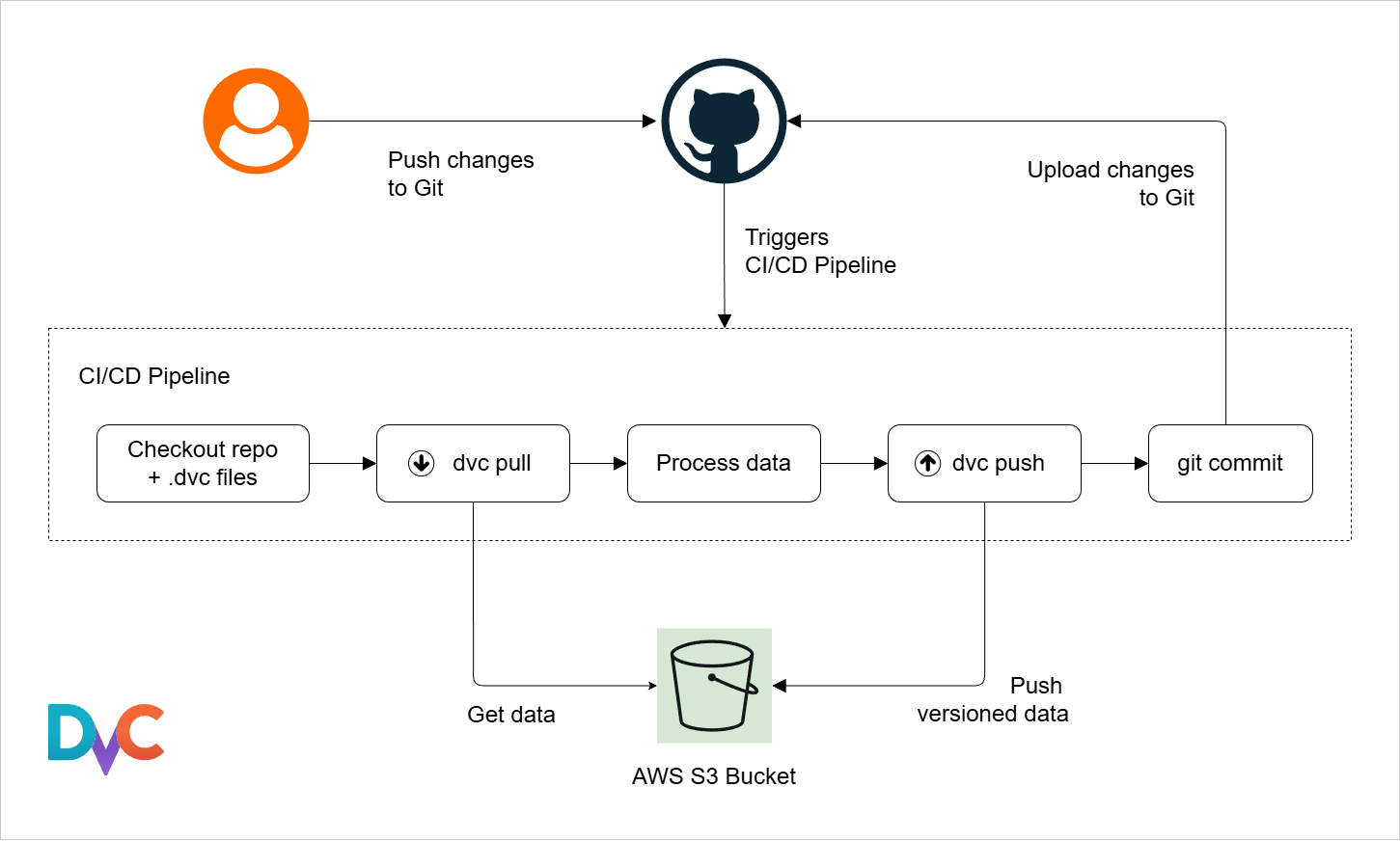
Data Version Control
DVC, or Data Version Control, is an open source tool for dataset versioning. It works together with Git.
- Git tracks code changes
- DVC tracks dataset changes
- Both work together in one workflow
DVC helps manage large datasets without storing them directly inside Git repositories.
For more information, please see DVC for Data Versioning.
Versioning ML Models
Model versioning tracks model changes across experiments and deployments.
- Track model updates
- Compare model performance
- Roll back older models
- Maintain experiment traceability
Example model versions:
- Model version 1.0 uses dataset version 1.0
- Model version 1.1 uses dataset version 1.1
- Model version 2.0 uses a different model architecture
Model versioning helps teams understand how datasets and training changes affect model performance.
MLflow for Model Versioning
MLflow can log model versions and experiment metadata.
- Track experiments
- Store model versions
- Compare runs
- Maintain experiment history
In the example below, mlflow.set_tag() stores the model version and mlflow.log_model() logs the trained model.
import mlflow
# Set version to 1.0
mlflow.set_tag("model_version", "1.0")
# Log model
with mlflow.start_run():
mlflow.log_model(model, "model")
Expected result:
Model logged successfully with version tag 1.0
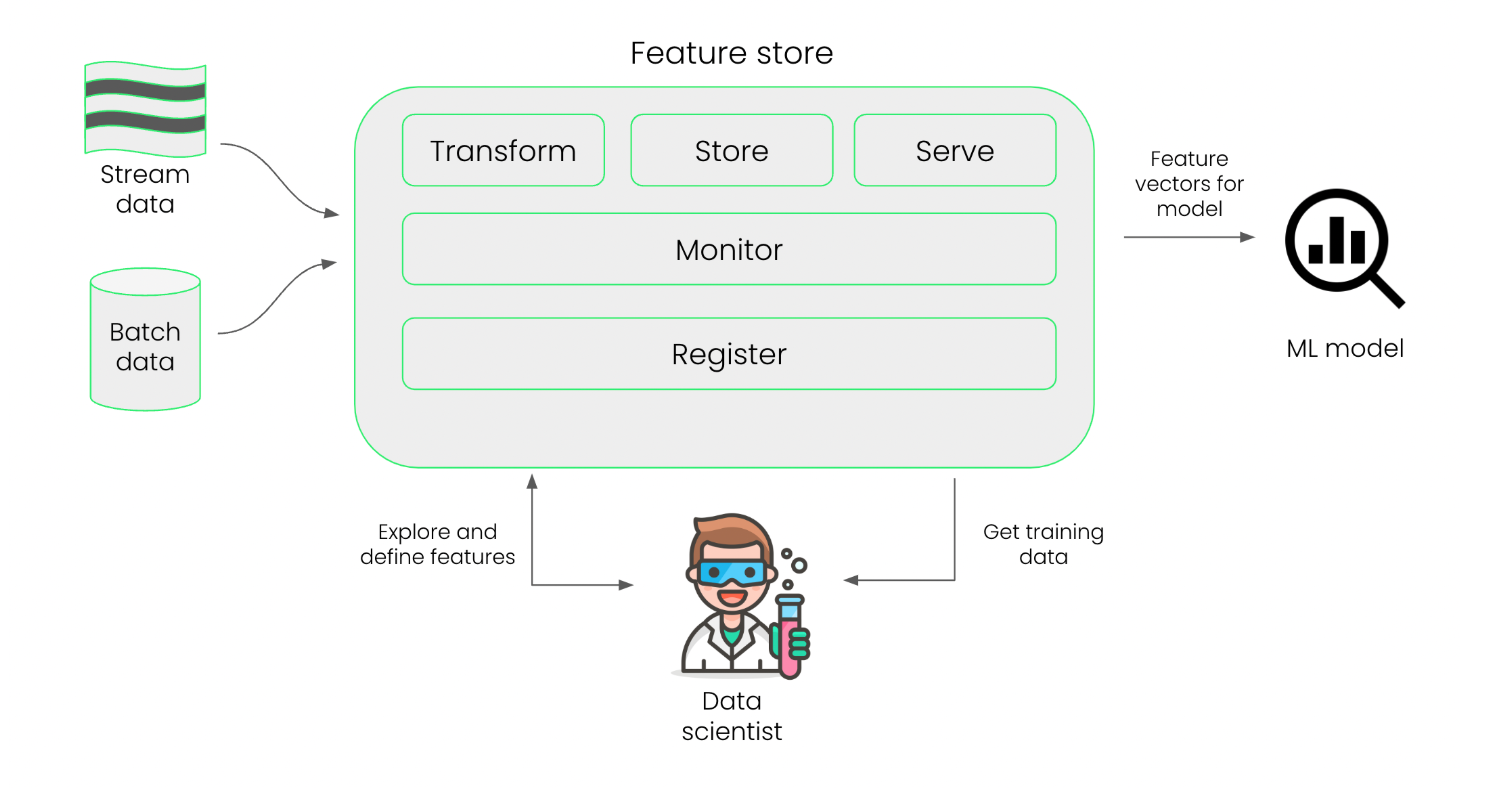
Feature Store
A feature store manages the versions of features across experiments, ensures consistent data usage in future tests, and avoids duplication. They help ensure the same features are used consistently during training and inference.
For more information, please see Feature Store.
Model Stores
A model store is like a feature store but for models. It ensures models can be reused and reproduced across experiments.
- Store trained models and metadata
- Enable version control and rollback
Model stores are commonly used together with feature stores and experiment tracking systems.