Feature Stores
Overview
Feature stores are central databases for storing data prepared for ML training and inference. They enables feature reuse across models.
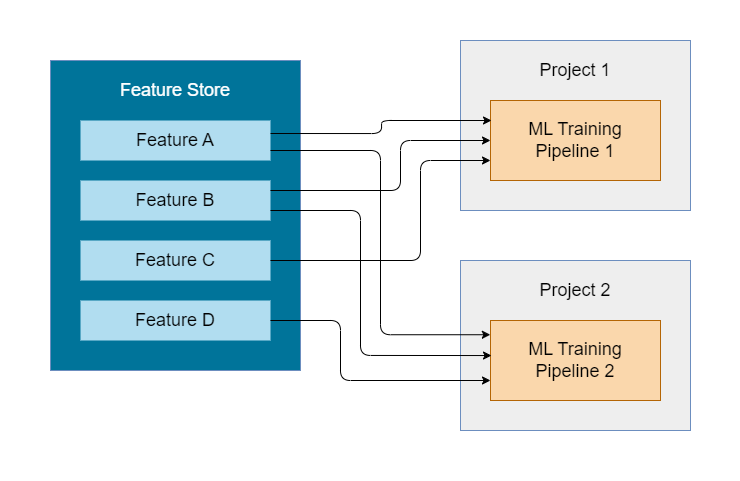
The feature store ensures data consistency across all stages, from development to production.
Dual Databases
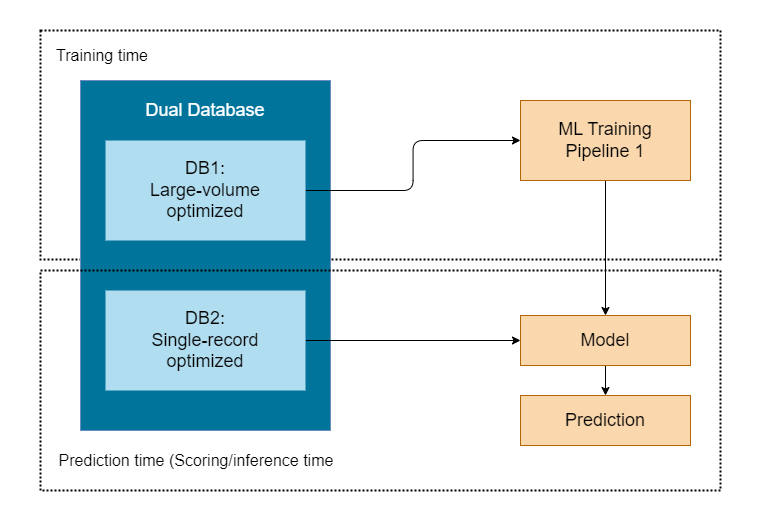
Feature stores are often implemented as dual databases which are consists of two databases:
- DB1 - highly optimized for large volumes of training data
- DB2 - for fast retrieval of records at prediction time
Benefits
A feature store helps teams avoid duplicating effort by sharing engineered features. It allows automated transformations and makes features consistent across experiments, training, and production.
- Faster experimentation – Reuse existing features instead of recreating them.
- Continuous training – Ensures models use up-to-date feature values.
- Reliable predictions – Provides the right features for accurate predictions.
- Environment symmetry – Prevents data mismatches between training and serving.
Environment Symmetry
Training and serving environments can sometimes use different features, causing data skew. This can lead to models performing well during training but poorly in production.
A feature store ensures consistency by serving as a single source for:
- Experimentation
- Continuous training
- Online predictions
This reduces feature engineering time and prevents training/serving skew. For example, a spam filter trained on clean text emails might fail if deployed on HTML emails.
