Architecture
High-Level Architecture
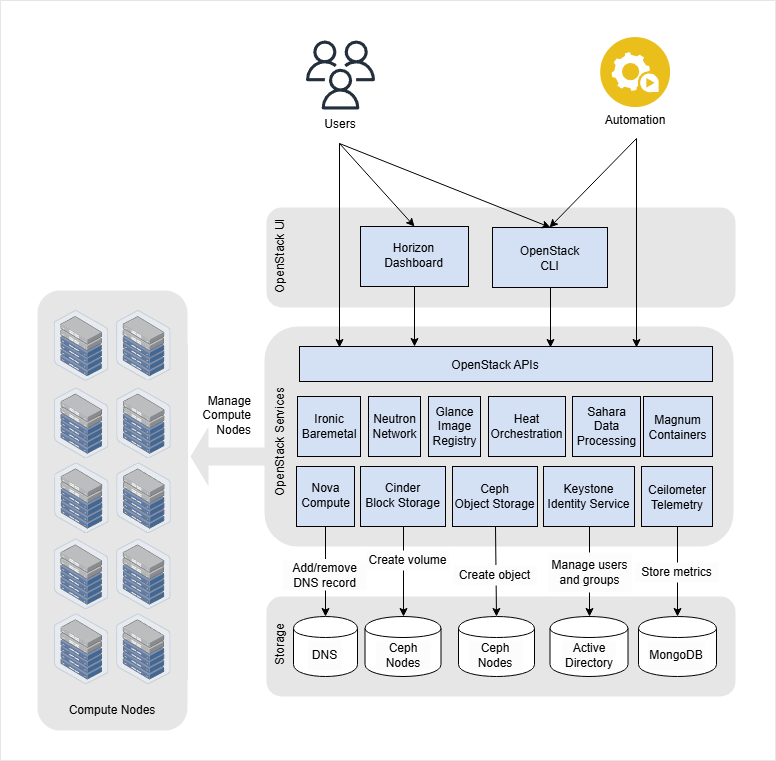
OpenStack follows a layered service architecture where each service has a specific role.
- Users access services through dashboards, CLIs, or platforms
- Services communicate with each other through APIs
- Shared infrastructure supports all services
This design allows each service to evolve independently while still working as part of a larger system.
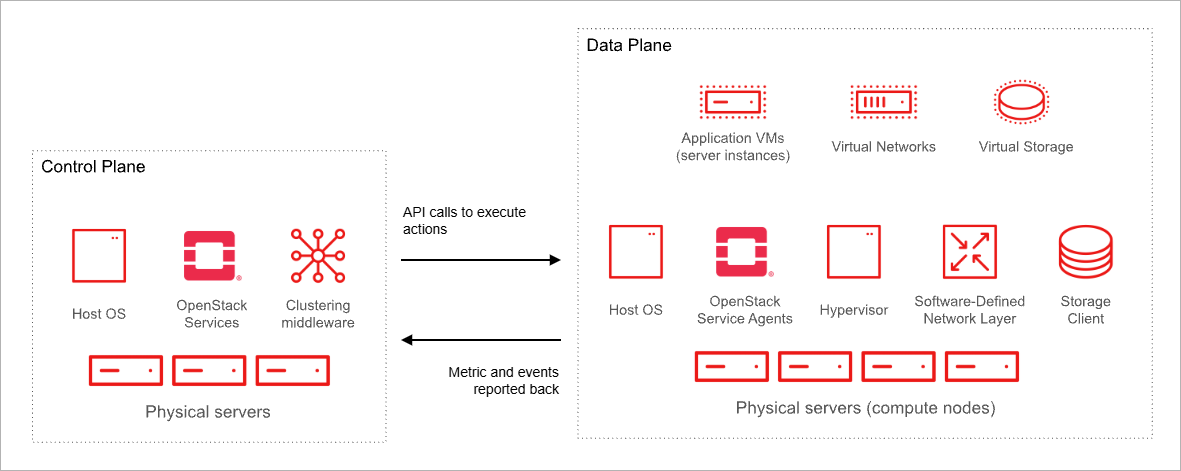
Control and Data Planes
OpenStack separates control and data planes to manage resources efficiently.
- Control plane handles requests and scheduling
- Data plane executes tasks on compute and storage hosts
Separating these planes ensures workloads keep running even when controllers are restarted. It also allows network traffic to be segmented for security and performance.
Control Plane Services
Control plane handles requests and scheduling.
| Service | Role | Description |
|---|---|---|
| Keystone | Identity | Authenticates users and manages credentials |
| Glance | Images | Streams VM images to compute nodes |
| Nova API | Compute | Schedules VM on a hypervisor using Placement |
| Neutron API | Networking | Creates network ports and sets up overlay tunnels |
| Cinder API | Block Storage | Attaches storage volumes to instances |
| Heat | Orchestration | Automates deployment of multi-service applications |
| Horizon / Skyline | Dashboard | Web interface for managing OpenStack resources |
Data Plane Agents
Data plane agents run on hosts.
| Agent | Role | Description |
|---|---|---|
| nova-compute | Compute | Runs on each hypervisor to manage VM lifecycle |
| neutron-OVS-agent | Networking | Configures Open vSwitch on compute hosts |
| cinder-volume | Storage | Manages backend storage volumes |
OpenStack Installation Layout
An OpenStack deployment consists of many components that must be installed in the correct order.
- Core services depend on identity services
- Supporting components like databases and message queues are required
- Some services can run in high availability mode
This structure ensures reliability and scalability as the environment grows.
Deployment Models
OpenStack can be deployed in different ways depending on scale and purpose.
- Single-node all-in-one deployments for testing
- Multi-node deployments for production use
- Separation between control plane and workload nodes
In production environments, management components are kept separate from user workloads for stability and performance.
Service Placement and Scalability
Each OpenStack service can run independently and be scaled as needed.
- Services can run on separate hosts or containers
- Multiple instances can be load balanced
- Horizontal scaling supports growing demand
This gives architects flexibility when designing hardware and network layouts.
API-based Communication Model
All OpenStack services communicate using REST APIs.
- Requests use standard HTTP methods
- Data is exchanged using JSON
- Each service listens on specific ports
Creating resources in OpenStack is done through API calls that may trigger internal workflows.
In the example below, a block storage volume is created by sending a request with parameters such as size and name.
POST /v3/volumes
Content-Type: application/json
{
"size": 10,
"name": "sample-volume"
}
The service responds with a JSON object containing identifiers and metadata, confirming the resource was created.
OpenStack Logical Architecture
OpenStack consists of multiple independent services that works together to provide infrastructure as a service, and all communication happens through APIs. The services can be swapped or updated as long as APIs stay consistent.
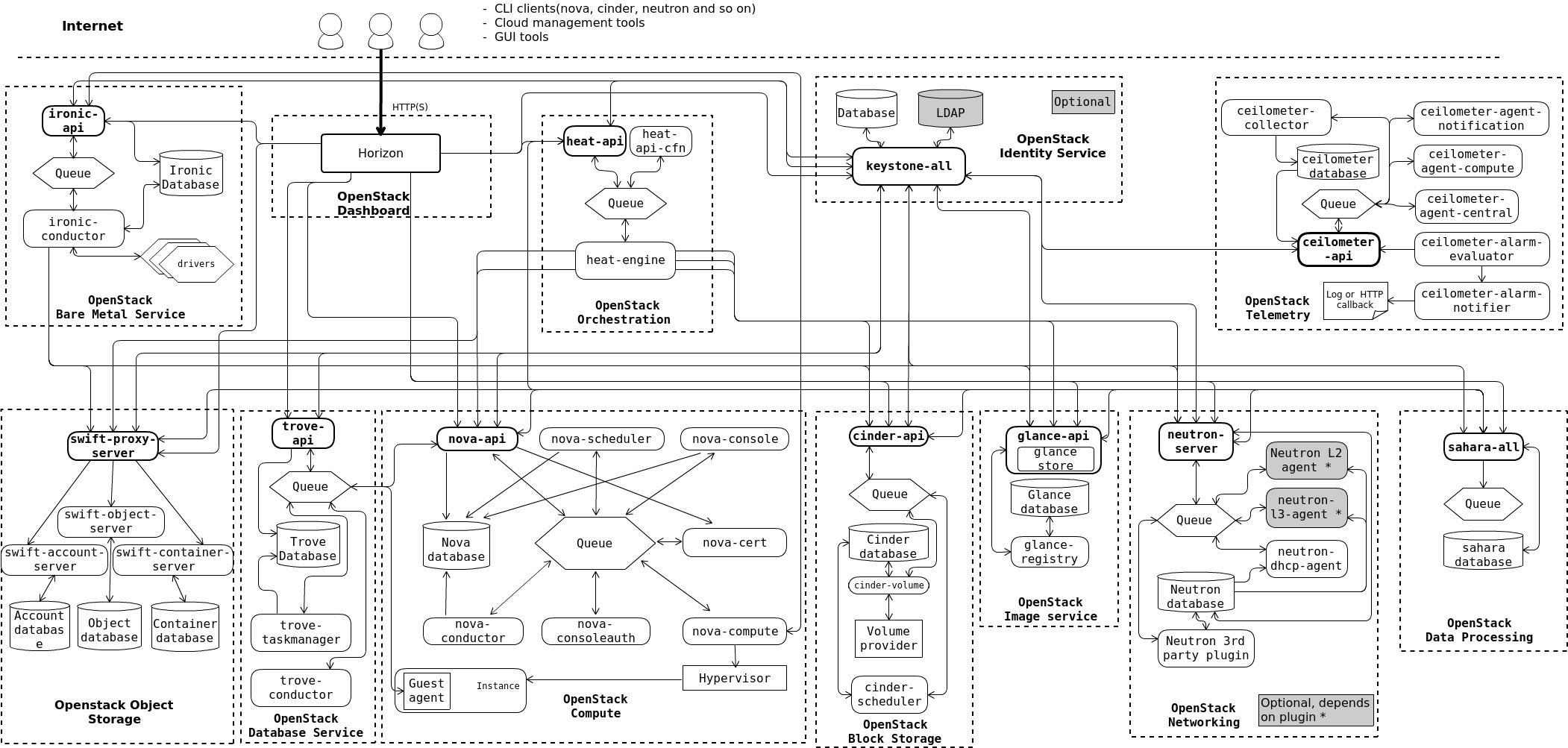
Each service has internal components that interact through processes and message queues. For example:
- Nova API receives requests and forwards them to other Nova components.
- Requests are sent through message brokers like RabbitMQ.
- Databases store service state, runtime data, and configuration.
- You can choose solutions like RabbitMQ, MySQL, MariaDB, or SQLite for deployment.