Infrastructure Planning
Overview
OpenStack needs careful planning because it runs on real infrastructure and depends on many supporting components.
- OpenStack runs on existing infrastructure
- Services communicate through APIs
- Control plane and user plane are separated
OpenStack depends on servers, networks, storage, and supporting software to function reliably. The goal is to design a stable control plane, reliable compute resources, and scalable network and storage backends.
Core Infrastructure Requirements
OpenStack services are mostly API-driven applications running on Linux. They need several core infrastructure components to work correctly.
| Component | Purpose | Common Options |
|---|---|---|
| Web servers | Expose service APIs | Apache, Nginx |
| Databases | Store service state and data | MySQL, MariaDB, PostgreSQL |
| Message queues | Handle internal async messaging | RabbitMQ |
| Cache services | Improve performance | Memcached |
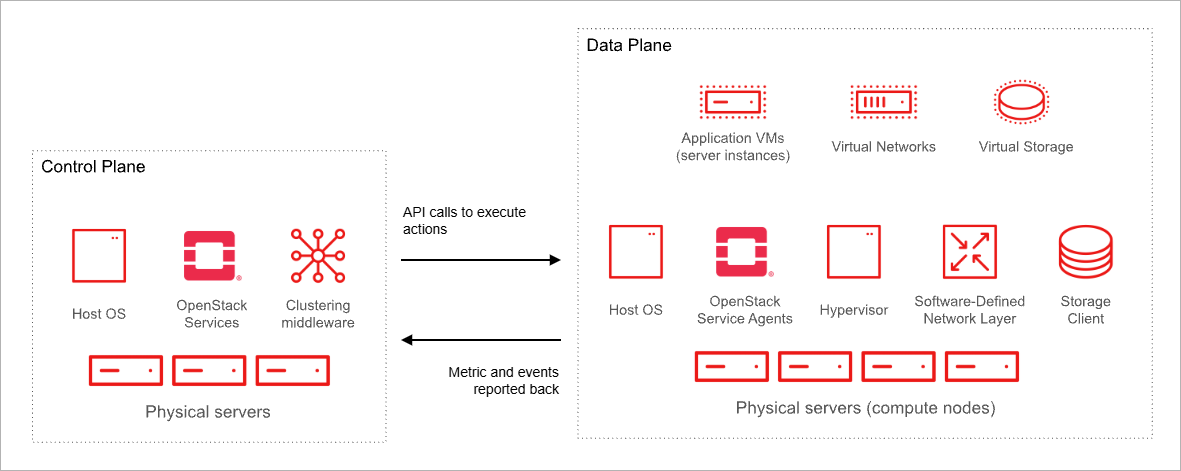
Control Plane
The control plane contains all management and decision-making components in OpenStack.
- API endpoints for all services
- Authentication and authorization
- Scheduling and coordination logic
Services like compute and networking split their components between control plane and user plane. Agents running on compute nodes cannot directly access databases. Instead, conductor services in the control plane relay and filter communication.
Control Plane High Availability
The control plane uses several mechanisms to stay stable and highly available. These mechanisms keep OpenStack services accessible during failures, reduce downtime, and support reliable scaling as the cloud grows.
| Mechanism | Purpose | Common Tools |
|---|---|---|
| Database clustering | Prevent data loss and improve availability | Galera |
| Load balancing for APIs | Distribute traffic and detect failures | HAProxy |
| Service orchestration | Monitor and restart failed services | Pacemaker |
Compute Resource Pool Planning
OpenStack supports multiple compute models, with virtual machines being the most common. Compute resources can be grouped, scheduled, and sized based on workload requirements and host capabilities.
| Factor | Description |
|---|---|
| Hypervisor support |
|
| Compute pools |
|
| Capability-based scheduling |
|
Availability zones and host aggregates ensure that workloads run on the most suitable hosts and improve performance and efficiency.
Compute Hardware Considerations
When selecting compute hardware, several factors must be considered to ensure optimal performance and resource utilization.
| Factor | Description |
|---|---|
| Instance density & workload patterns |
|
| Overcommit ratios |
|
| Hardware acceleration |
|
These factors define how VMs are sized and how resources are allocated. Overcommitment allows physical hardware to host more virtual resources than its actual capacity, and improves efficiency while maintaining predictable performance.
The table below illustrates how overcommitment works in practice:
| Resource | Physical Hardware | Virtual Allocation | Notes |
|---|---|---|---|
| CPU | 12 cores | 192 vCPUs | With default 16:1 ratio, each physical core supports 16 virtual CPUs |
| RAM | 256 GB | 384 GB | With 1.5:1 ratio, virtual memory exceeds physical memory |
| VM Flavor Example | 4 vCPUs, 8 GB RAM | 48 instances | Scheduler can run 48 M1 Large instances on this node |
Overcommitment ratios can be changed based on workload requirements or operational priorities. This helps administrators maintain a balance between efficiency, cost, and performance.
Physical Network Design
The physical network, or underlay, carries all OpenStack traffic. It must be reliable, redundant, and high-performing to support production workloads.
| Factor | Details |
|---|---|
| Traffic segmentation |
|
| VLAN vs VXLAN |
|
| Redundant paths |
|
| Performance & latency |
|
| Network acceleration |
|
High network performance is essential for demanding workloads such as telecom or real-time systems. Acceleration technologies improve throughput and reduce latency, which ensures predictable and efficient operations.
Software-Defined Networking
OpenStack networking is mostly implemented in software, which allows flexible and scalable network management.
| Factor | Details |
|---|---|
| Virtual networks | OpenStack creates virtual networks and subnets for tenant isolation and traffic control |
| VXLAN tunneling | Hosts communicate over VXLAN tunnels to enable overlay networks across physical nodes |
| SDN options | Multiple software-defined networking solutions are available |
For small deployments, Linux Bridge is commonly used, while Open vSwitch is preferred for larger environments. More complex networks can integrate with external SDN platforms to provide advanced features and improved scalability.
OpenStack supports both open-source and commercial SDN controllers. Examples include:
- OpenContrail
- OpenDaylight
- VMware NSX
- Cisco ACI
Storage Backend Planning
Storage design should match existing infrastructure and workload needs. A well-planned storage backend provides compute nodes with fast and reliable access to data.
| Type | Considerations |
|---|---|
| Hardware storage backends |
|
| Software-defined storage |
|
| Data path design |
|
Planning for Additional Services
Core services are only part of a full OpenStack deployment. Additional services need careful planning to ensure scalability and reliability.
-
Monitoring and telemetry
- Tracks system performance
- Supports proactive issue detection
- Adds extra network and storage load
-
Database and container services
- May require large instances
- Needs replication for high availability
-
Future expansion needs
- Planning ahead prevents resource shortages
- Supports smooth scaling of workloads
- Prepares for new services and users