Handling Agent Failures
Overview
Even well-designed agents will fail sometimes. Production systems must be built to handle failures safely and predictably.
- Handle tool failures
- Manage retries and caching
- Control task dependencies
- Enforce strict authentication
The goal is not to eliminate failure, but to design systems that recover smoothly and protect users and data.
Tool Call Failures
Tool failures are common in agent systems. They can happen when parameters are wrong, outputs are misunderstood, or external services are unavailable.
- Incorrect parameters
- Misinterpreted outputs
- Authentication or downtime issues
To reduce these risks, define clear tool schemas and usage guidelines.
- Add validation checks for tool inputs and outputs
- Verify the correct tool is selected before execution
- Use standardized protocols to reduce integration errors
Retry Mechanisms with Backoff
External APIs may become slow or temporarily unavailable. Instead of failing immediately, use a retry strategy.
- Retry failed requests
- Use exponential backoff
- Inform users about delays
Exponential backoff increases the wait time between retries. This reduces pressure on busy services while giving them time to recover.
In the example below, the variable max_retries defines how many attempts are allowed, and delay controls the wait time between retries.
import time
import random
max_retries = 3
delay = 1
for attempt in range(max_retries):
try:
result = call_external_api()
print("Success:", result)
break
except Exception:
print("Retrying...")
time.sleep(delay)
delay *= 2
Result:
If the service recovers, the request succeeds. If not, the system stops after the defined retries and can return a fallback message to the user.
Caching as a Fallback
Caching stores previous tool responses for reuse.
- Store previous results
- Use as fallback during outages
- Best for static or slow-changing data
Caching works well for documentation, historical records, or configuration data. It does not work well for real-time information such as live prices or active system states.
Choosing between retries and caching depends on how dynamic the data is. Use retries for frequently changing data, then use caching for mostly static data to improve reliability.
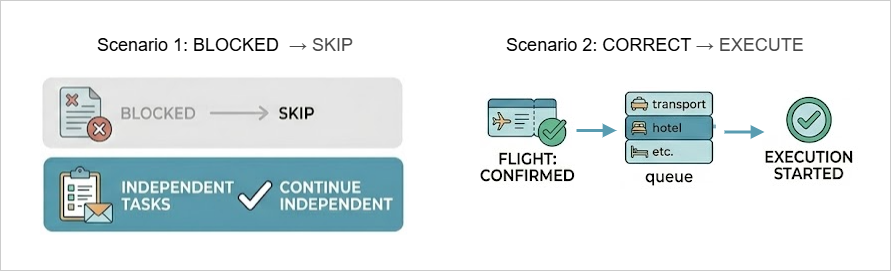
Queue Management for Dependent Tasks
Some tasks depend on others. If one fails, others should wait or adjust.
- Manage task order
- Trigger agents when ready
- Prevent blocking workflows
For example, a transport booking should not start before a flight is confirmed. Intelligent queue management ensures agents execute in the correct sequence. It can also skip blocked tasks and continue with independent ones.
Authentication and Access Control
Agents often need permission to access tools and data. Without strict controls, they may access sensitive information.
-
Assign unique agent identities
- Enables role-based permissions and clear audit trails
- Helps track agent actions for security and compliance
-
Restrict access to isolated environments
- Limits agents to only the systems or data they need
- Reduces risk of accidental or unauthorized access
-
Define clear action limits
- Prevents agents from performing high-risk operations without approval
- Ensures agents stay within safe operational boundaries
For example, an IT support agent may reset passwords but should not delete user accounts. Clear boundaries protect both users and systems.