Building Blocks
Using Text Data
Computers themselves cannot read or understand text like humans do.
- They only process numbers, not words or emotions
- Sentences like “I am a data scientist” have no meaning to them
- They rely on patterns and structure rather than understanding language directly
Natural Language Processing (NLP) bridges this gap by converting text into numerical form. It enables machines to detect context, recognize meaning, and make sense of language. This allows LLMs to transform raw text into intelligent, human-like responses.
Linguistic Subtleties
LLMs extend NLP’s capabilities by recognizing subtle meaning in language. LLM can detect linguistic subtleties like:
- Irony
- Humor
- Pun
- Sarcasm
- Intonation
- Intent
For example, if asked “What’s your favorite book?”, an LLM might say:
“That’s a tough one. My all-time favorite is To Kill a Mockingbird. Have you read it?”
This makes interactions sound natural, not robotic.
How LLMs Are Trained
LLMs are called “large” because they are trained on huge amounts of data and contain many parameters. Parameters are the patterns and rules learned during training, and more parameters mean the model can understand more complex relationships and produce more accurate responses.
As models grow in scale, they start developing new abilities not seen in smaller ones. Scale depends on two main factors:
- The size of the training data
- The number of model parameters
When this scale crosses a certain point, performance can suddenly improve, leading to new skills and deeper understanding. To reach that stage, LLMs go through several key training steps:
- Text preprocessing
- Text representation
- Pre-training on large datasets
- Fine-tuning for specific tasks
- Advanced fine-tuning for higher accuracy
These steps help LLMs learn structure, meaning, and context, allowing them to respond intelligently and adapt to complex language patterns.
Text Preprocessing
Text preprocessing organizes and simplifies raw text before analysis.
- Includes tokenization, stop word removal, and lemmatization
- Steps can happen in any order depending on the task
- Each step reduces noise and highlights useful words
This process ensures that only meaningful words remain, making analysis more accurate.
Tokenization
Tokenization breaks sentences into smaller parts called tokens.
- Each word or punctuation mark becomes a token
- Turns text into a list of separate items
Example:
text = "Working with natural language processing is tricky."
tokens = ["Working", "with", "natural", "language", "processing", "is", "tricky", "."]
This step turns sentences into a structured list that computers can easily handle.
Stop Word Removal
Some common words add little meaning to a sentence.
- Words like “is”, “with”, “the” are called stop words
- Removing them helps focus on meaningful content
Example:
Before stop word removal:
["Working", "with", "natural", "language", "processing", "is", "tricky", "."]
After removal, only the key parts of the sentence remain:
["Working", "natural", "language", "processing", "tricky", "."]
Lemmatization
Lemmatization simplifies different forms of a word into their base form.
- Groups similar words like “talked”, “talking”, and “talk”
- Reduces redundancy and improves pattern recognition
Example:
from nltk.stem import WordNetLemmatizer
lem = WordNetLemmatizer()
print(lem.lemmatize("talked"))
print(lem.lemmatize("talking"))
Expected output:
talk
talk
This keeps word meaning consistent across variations.
Text Representation
Once preprocessed, text must be converted into numbers that machines understand.
- Text representation turns words into numerical values
- Common methods include bag-of-words and word embeddings
- Enables LLMs to process and learn from large text datasets
This transformation makes human language machine-readable. Some common methods to do this:
- Bag-of-words
- Word embeddings
Bag-of-Words
Bag-of-words counts how often each word appears.
- Creates a matrix showing word frequency
- Treats each sentence as a collection of words, not a sequence
Using this text as example:
The cat chased the mouse swiftly", "The mouse chased the cat
Code:
from sklearn.feature_extraction.text import CountVectorizer
sentences = ["The cat chased the mouse swiftly", "The mouse chased the cat"]
vectorizer = CountVectorizer(stop_words='english')
matrix = vectorizer.fit_transform(sentences)
print(vectorizer.get_feature_names_out())
print(matrix.toarray())
Expected output:
['cat' 'chased' 'mouse' 'swiftly']
[[1 1 1 1]
[1 1 1 0]]
While simple, Bag-of-words can’t capture context or relationships between words.
- Misses opposite meanings in similar sentences
- Treats related words as unrelated
- Fails to understand sentence structure
Because of these limits, it’s often replaced by more advanced methods like word embeddings.
Word Embeddings
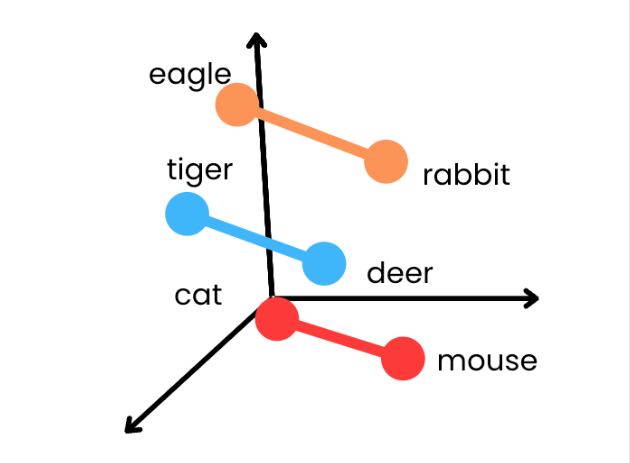
Word embeddings represent words using numbers that reflect their meanings.
- Similar words have similar number patterns
- Captures relationships like “cat hunts mouse” or “tiger hunts deer”
- Each word becomes a vector (a list of numbers)
Example (simplified):
cat = [-0.9, 0.9, 0.9]
mouse = [0.8, -0.7, 0.7]
This helps LLMs understand not just words but also their relationships and context.
Fine-Tuning LLMs
Fine-tuning allows smaller teams to benefit from many existing pre-trained models without needing massive resources. It improves a model’s understanding of a particular topic.
- A pre-trained model already knows general language patterns
- Fine-tuning teaches it specialized terms and styles
- The process adjusts the model slightly rather than rebuilding it
It’s like a person who already speaks a language learning new words in a specific field, such as medicine or law. This helps the model communicate better in that domain.
Challenges with Large Models
LLMs are powerful but also difficult and expensive to manage.
- Require huge computing power and storage
- Need large-scale infrastructure
- Depend on vast amounts of data and time
Building and training them from scratch demands advanced hardware and reliable systems, which most organizations cannot afford.
Efficient Model Training
Training must also be efficient to save time and costs.
- Large models can take weeks or months to train
- Efficient training reduces time using better algorithms
- Parallel processing shortens overall training duration
For instance, training a huge LLM on one GPU could take centuries, but optimized setups finish the same job within weeks.
Data Availability
Another challenge is the need for high-quality training data to accurately learn the complexities and subtleties of language.
- LLMs are trained on hundreds of gigabytes of text
- This equals millions of books and online articles
- Poor-quality data leads to inaccurate or biased results
Since fine-tuning uses much smaller datasets, data quality matters even more to ensure reliable performance.
Overcoming These Challenges
Fine-tuning helps manage the complexity of LLMs bt:
- Adapts a general model to a focused use case
- Reduces the need for massive computing power
- Makes AI accessible to smaller teams and projects
Because fine-tuned models already understand general language, they can quickly learn specialized knowledge with minimal resources.
Fine-Tuning vs Pre-Training
Fine-tuning and pre-training differ mainly in scale and purpose.
- Fine-tuning uses fewer resources and less time
- Requires only one CPU or GPU in many cases
- Uses small datasets (hundreds of MBs to a few GBs)
- Pre-training uses massive data (hundreds of GBs) and thousands of GPUs
Fine-tuning is faster, cheaper, and ideal for adapting existing models, while pre-training builds new models from scratch. Both are important, but fine-tuning makes advanced language models practical for everyday use.
Transfer Learning
Transfer learning allows a model to use what it has already learned to perform new, related tasks.
- Applies existing knowledge to new problems
- Saves time and training resources
- Improves performance on small datasets
For example, someone who learns to play the piano can easily pick up the guitar because of shared concepts like rhythm and notes. Similarly, an LLM trained on general language can apply that understanding to specific tasks with little extra data.
Common learning techniques:
- Zero-shot learning - No explicit training
- One-shot learning - Learn new task with few examples
- Multi-shot learning - Requires more examples than few-shot
Zero-Shot Learning
Zero-shot learning lets LLMs perform new tasks without being explicitly trained for them.
- No specific examples are used
- Relies on existing language understanding
- Transfers general knowledge to new situations
Example:
If a model knows what a “horse” is and is told a “zebra” looks like a striped horse, it can identify a zebra correctly without prior examples.
Few-Shot Learning
Few-shot learning helps models learn a new task with only a few examples.
- Builds on previous knowledge
- Learns from limited samples
- Reduces the need for massive datasets
Example:
A student recalls lessons from class and answers a similar question in an exam, even without extra studying. Similarly, an LLM uses a few examples to adapt to new tasks.
Multi-Shot Learning
Multi-shot learning is similar to few-shot learning but uses more examples for better accuracy.
- Uses more examples per task
- Builds stronger understanding
- Improves precision and generalization
Example:
If the model sees several images of Golden Retrievers, it can learn to recognize them and later identify similar breeds, like Labradors, with higher confidence.