Optimizing AI
Metrics
When building AI-powered systems, there are three key metrics to track.
-
Latency
- Impacts user experience and perceived speed
- Faster models improve responsiveness but may reduce output quality
- Often trades off with accuracy in more complex tasks
-
Token cost
- Depends on both input and output token usage
- Can be reduced by limiting context and response length
- Important for controlling API usage costs at scale
-
Output quality
- In coding, it includes whether the code runs correctly
- Evaluates how well the response solves the task
- Often increases when latency and cost also increase
Model Benchmarking
Benchmarks are used to compare how well models perform on specific tasks, especially in code generation.
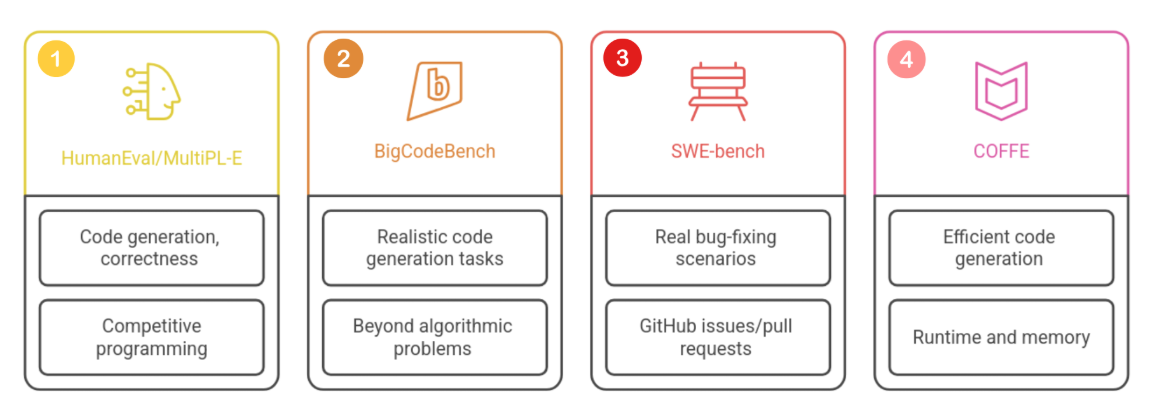
Some well-known benchmarks include:
- HumanEval and MultiPL-E focus on functional correctness in coding tasks
- BigCodeBench focuses on more realistic software engineering problems
- SWE-bench evaluates real-world bug fixing using GitHub issues and pull requests
- COFFE measures both correctness and performance like speed and memory usage
Each benchmark evaluates models differently, so results should be interpreted based on the task context.
Prompt Versioning
Prompting is an iterative process, so prompts should be managed like code.
- Store prompts in version-controlled systems
- Add version tags to track changes
- Use rollback when newer prompts reduce performance
This makes prompts easier to maintain and improves reproducibility across projects.
Another useful practice is using placeholders inside prompts. This allows reuse without rewriting the entire prompt each time.

Prompt Caching
Prompt caching helps reduce repeated computation by reusing previous results.
It works by storing:
- Prompt
- Input
- Model configuration
- Temperature settings
If a similar request appears again, the system can reuse or adapt a previous response instead of making a new API call. This reduces cost and improves speed, especially in systems with repeated or similar queries.
Additional:
When context becomes large, token costs can grow quickly. One effective strategy is to combine related subtasks into a single prompt when they share the same context. This reduces repetition and improves efficiency while keeping outputs consistent.