Cluster Maintenance
OS Upgrade
When a node goes down briefly and comes back, the kubelet process restarts, and the Pods return online. If a node is down for more than 5 minutes, the Pods on that node are terminated.
If a Pod is part of a ReplicaSet, it will be recreated on another available node.
For maintenance, you can drain a node to ensure Pods are gracefully terminated and rescheduled on another node before the main node goes down.
kubectl drain node-1
To prevent new Pods from being scheduled on a node, you can cordon it. This doesn’t affect running Pods, just prevents new ones from being scheduled.
kubectl cordon node-1
When the node is back, it won’t serve Pods until you uncordon it. Note that existing Pods won’t automatically move to the new node, but new Pods can be scheduled there.
kubectl uncordon node-1
Kubernetes Software Versions
To check the Kubernetes version for your nodes:
kubectl get nodes
Output:
NAME STATUS ROLES AGE VERSION
master Ready <none> 7h21m v1.11.3
worker1 Ready <none> 7h21m v1.11.3
worker2 Ready <none> 7h21m v1.11.3
The version number:

Kubernetes only supports the three most recent versions.
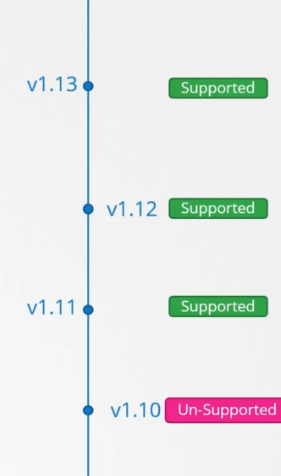
Upgrading the Cluster
For managed Kubernetes clusters, updates are handled through the Management Console. For clusters created with kubeadm, the upgrade process is:
- Upgrade the master node.
- Upgrade the worker nodes.
You can upgrade worker nodes in several ways:
- All at once: The whole cluster goes down.
- One node at a time: The workload is moved to other nodes while upgrading.
- Add new nodes: Move workloads to new nodes with the latest software and remove old nodes.
Backup and Restore
Resource Configs
To back up all resource configs in all namespaces:
kubectl get all --all-namespaces -o yaml > all-resources.yml
Alternatively, store all manifests in a Git repository.
etcd
To back up the etcd server, back up the data directory:
/var/lib/etcd
You can also use etcdctl to create a snapshot:
ETCDCTL_API=3 etcdctl \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/peer.crt \
--key=/etc/kubernetes/pki/etcd/peer.key \
snapshot save /snapshots/backup.db
To restore from the snapshot:
ETCDCTL_API=3 etcdctl \
snapshot restore /snapshots/backup.db \
--data-dir /var/lib/etcd-from-backup \
--initial-cluster master-1=https://192.168.3.10:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls https://${INTERNAL_IP}:2380
Alternatively, use nerdctl, a Docker-compatible CLI for containerd:
sudo nerdctl run --rm \
-v '/snapshots:/snapshots' \
-v '/var/lib/etcd:/var/lib/etcd' \
-e ETCDCTL_API=3 \
'k8s.gcr.io/etcd:3.5.3-0' \
/bin/sh -c "etcdctl snapshot restore --data-dir /var/lib/etcd /snapshots/backup.db"
Finally, reload the daemon and restart etcd:
systemctl daemon-reload
systemctl restart etcd