Merging Data
Overview
In data analysis, merging combines two datasets into one based on a common column or index. Pandas provides powerful functions like merge() for this purpose.
Example tables:
Table A:
| x | y | z |
|---|---|---|
| 1 | 10 | 20 |
| 2 | 15 | 25 |
| 3 | 20 | 30 |
Table B:
| x | y | w |
|---|---|---|
| 1 | 50 | 100 |
| 2 | 60 | 110 |
| 4 | 70 | 120 |
First, make sure to create the dataframes:
import pandas as pd
table_a = pd.DataFrame({
'x': [1, 2, 3],
'y': [10, 15, 20],
'z': [20, 25, 30]
})
table_b = pd.DataFrame({
'x': [1, 2, 4],
'y': [50, 60, 70],
'w': [100, 110, 120]
})
To merge Table A and Table B on column "x":
merged_data = table_a.merge(table_b, on='x')
print(merged_data)
Output:
| x | y_x | z | y_y | w |
|---|---|---|---|---|
| 1 | 10 | 20 | 50 | 100 |
| 2 | 15 | 25 | 60 | 110 |
To see more examples, please see Merging Data with Pandas Notebook.
Set Custom Suffixes
To distinguish columns with the same name, you can use the suffixes parameter.
merged_data_custom = table_a.merge(table_b, on='x', suffixes=('_A', '_B'))
print(merged_data_custom)
Output:
| x | y_A | z | y_B | w |
|---|---|---|---|---|
| 1 | 10 | 20 | 50 | 100 |
| 2 | 15 | 25 | 60 | 110 |
Merging Multiple DataFrames
Merging multiple DataFrames allows you to combine related data from different tables into a single table for analysis. This is useful when data is spread across multiple sources.
To merge two tables:
merged_df = df1.merge(df2, on='id')
To merge three tables:
merged_df = df1.merge(df2, on='id') \
.merge(df3, on='id')
To merge four tables (and so on):
merged_df = df1.merge(df2, on='id') \
.merge(df3, on='id') \
.merge(df4, on='id')
To see more examples, please see Merging Data with Pandas Notebook.
Left Join
A left join keeps all rows from the left table and only matching rows from the right table.
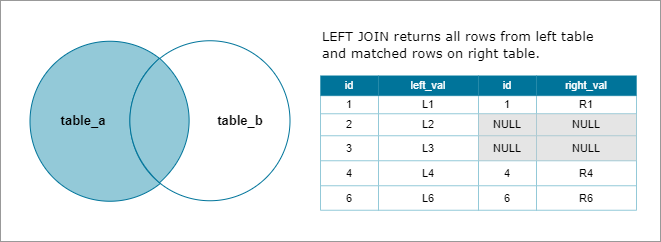
Example: Two tables, "left" and "right," merged on column C
- All rows from "left" are included
- Only matching rows from "right" are included
- If no match, right-side values are null
As an example, we'll use the following tables:
-
movies-
Contains movie details
-
Title, popularity, and unique ID
movie_id title popularity 1 Inception 90.5 2 Interstellar 87.3 3 The Dark Knight 95.0 4 Tenet 75.2 5 Dunkirk 80.4 6 Memento 70.1
-
-
taglines-
Contains movie taglines:
-
Movie ID and tagline text
movie_id tagline 1 "Your mind is the scene of the crime." 2 "Mankind was born on Earth. It was never meant to die here." 3 "Welcome to a world without rules." 5 "When 400,000 men couldn’t get home, home came for them."
-
To combine the tables using a left join:
- Merge on the
movie_idcolumn - Use
how='left'to specify a left join - Movies without a matching tagline get a null value (NaN in pandas)
The code:
import pandas as pd
movies = pd.DataFrame({
'movie_id': [1, 2, 3, 4, 5, 6],
'title': ["Inception", "Interstellar", "The Dark Knight", "Tenet", "Dunkirk", "Memento"],
'popularity': [90.5, 87.3, 95.0, 75.2, 80.4, 70.1]
})
taglines = pd.DataFrame({
'movie_id': [1, 2, 3, 5],
'tagline': [
"Your mind is the scene of the crime.",
"Mankind was born on Earth. It was never meant to die here.",
"Welcome to a world without rules.",
"When 400,000 men couldn’t get home, home came for them."
]
})
merged_table = movies.merge(taglines, on="movie_id", how="left")
print(merged_table)
Expected output:
| movie_id | title | popularity | tagline |
|---|---|---|---|
| 1 | Inception | 90.5 | "Your mind is the scene of the crime." |
| 2 | Interstellar | 87.3 | "Mankind was born on Earth. It was never meant to die here." |
| 3 | The Dark Knight | 95.0 | "Welcome to a world without rules." |
| 4 | Tenet | 75.2 | NaN (no match found) |
| 5 | Dunkirk | 80.4 | "When 400,000 men couldn’t get home, home came for them." |
| 6 | Memento | 70.1 | NaN (no match found) |
To count the number of rows with missing taglines, we can use isnull() function to find the rows then count them using sum().
missing = merged_table['tagline'].isnull().sum()
print(missing)
This will return the number of rows, which is only two rows.
Right Join
A right join returns all rows from the right table and only matching rows from the left table. If no match is found, columns from the left table will be null.
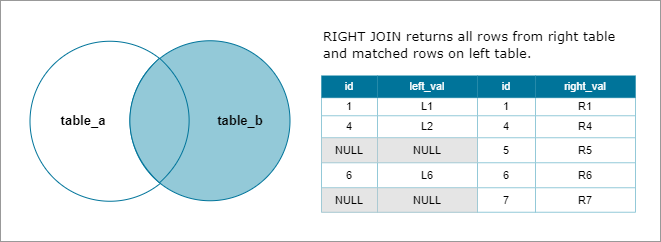
Example tables:
-
moviesid title popularity 1 Inception 90.5 2 Interstellar 87.3 3 The Dark Knight 95.0 4 Tenet 75.2 5 Dunkirk 80.4 6 Memento 70.1 -
tv_genremovie_id genre 3 Action 5 War 7 TV Movie 8 TV Movie
We use pandas to perform a right join. Note that the movies table uses id, while the tv_genre table uses movie_id.
import pandas as pd
movies = pd.DataFrame({
'id': [1, 2, 3, 4, 5, 6],
'title': ["Inception", "Interstellar", "The Dark Knight", "Tenet", "Dunkirk", "Memento"],
'popularity': [90.5, 87.3, 95.0, 75.2, 80.4, 70.1]
})
tv_genre = pd.DataFrame({
'movie_id': [3, 5, 7, 8],
'genre': ["Action", "War", "TV Movie", "TV Movie"]
})
# Performing the Right Join
merged_table = movies.merge(tv_genre, left_on="id", right_on="movie_id", how="right")
print(merged_table)
Expected output:
| id | title | popularity | movie_id | genre |
|---|---|---|---|---|
| 3 | The Dark Knight | 95.0 | 3 | Action |
| 5 | Dunkirk | 80.4 | 5 | War |
| NaN | NaN | NaN | 7 | TV Movie |
| NaN | NaN | NaN | 8 | TV Movie |
Self Join
Merging a table to itself, also called a self join, helps link related data within the same table. Self joins are useful for:
- Hierarchical data (e.g., employees and managers)
- Sequential relationships (e.g., logistics tracking)
- Graph data (e.g., social networks)
As an example, let's use the 'sequels` table which contains:
movie_id: Unique ID for each movietitle: Movie namesequel: ID of its sequel (if any)
| movie_id | title | sequel |
|---|---|---|
| 862 | Toy Story | 863 |
| 863 | Toy Story 2 | 10193 |
| 10193 | Toy Story 3 | NULL |
To display movies with their sequels in one row, we merge the table to itself.
import pandas as pd
sequels = pd.DataFrame({
"movie_id": [862, 863, 10193],
"title": ["Toy Story", "Toy Story 2", "Toy Story 3"],
"sequel": [863, 10193, None]
})
# Self merge
merged = sequels.merge(sequels,
left_on="sequel",
right_on="movie_id",
suffixes=("_org", "_seq"))
# Print only these 2 columns
result = merged[["title_org", "title_seq"]]
print(result)
Output:
title_org title_seq
0 Toy Story Toy Story 2
1 Toy Story 2 Toy Story 3
Merging on Indexes
Merging tables isn't limited to columns. We can also merge using indexes, which are often unique identifiers in DataFrames.
Table with an Index
Tables usually have an auto-incrementing index, but we can also set a specific column (like id) as the index.
import pandas as pd
movies = pd.DataFrame({
"id": [1, 2, 3, 4, 5, 6, 7, 8],
"title": ["Inception", "Titanic", "Avatar", "Interstellar", "The Dark Knight", "Pulp Fiction", "Forrest Gump", "The Matrix"]
}).set_index("id") # Setting 'id' as the index
print(movies)
Output:
title
id
1 Inception
2 Titanic
3 Avatar
4 Interstellar
5 The Dark Knight
6 Pulp Fiction
7 Forrest Gump
8 The Matrix
Setting an Index
We can set the index when reading a CSV using index_col in read_csv().
movies = pd.read_csv("movies.csv", index_col="id")
This ensures id is the index when loading the table.
Merging on Index
We can merge two tables using their index instead of a column. If the index name is id, the merge method accepts it just like a column name.
Create the taglines table:
taglines = pd.DataFrame({
"id": [1, 2, 3, 4, 5, 6, 7, 8],
"tagline": [
"Your mind is the scene of the crime.",
"Nothing on Earth could come between them.",
"Enter the world of Pandora.",
"Mankind was born on Earth. It was never meant to die here.",
"Welcome to a world without rules.",
"You won't know the facts until you've seen the fiction.",
"Life is like a box of chocolates.",
"Reality is a thing of the past."
]
}).set_index("id")
Now merge the taglines table to the movies table.
merged_df = movies.merge(taglines, on="id", how="left")
print(merged_df)
Output:
title tagline
id
1 Inception Your mind is the scene of the crime.
2 Titanic Nothing on Earth could come between them.
3 Avatar Enter the world of Pandora.
4 Interstellar Mankind was born on Earth. It was never meant to die here.
5 The Dark Knight Welcome to a world without rules.
6 Pulp Fiction You won't know the facts until you've seen the fiction.
7 Forrest Gump Life is like a box of chocolates.
8 The Matrix Reality is a thing of the past.
Here, id is the index, and the output retains the same structure, just with id as the index.
MultiIndex Merge
Some tables have multiple levels of indexing, such as movie and cast IDs. We can merge on multiple index levels just like merging on multiple columns.
Create the samuel and cast tables.
samuel = pd.DataFrame({
"movie_id": [1, 2, 3, 4, 5, 6, 7, 8],
"cast_id": [101, 102, 103, 104, 105, 106, 107, 108],
"actor": ["Samuel L. Jackson"] * 8
}).set_index(["movie_id", "cast_id"])
cast = pd.DataFrame({
"movie_id": [1, 2, 3, 4, 5, 6, 7, 8],
"cast_id": [101, 102, 103, 104, 105, 106, 107, 108],
"role": ["Agent", "Detective", "Soldier", "Explorer", "Vigilante", "Hitman", "Runner", "Hacker"]
}).set_index(["movie_id", "cast_id"])
Merge the cast table to the samuel table using the two indexes.
merged_df = samuel.merge(cast, on=["movie_id", "cast_id"], how="inner")
print(merged_df)
Output:
actor role
movie_id cast_id
1 101 Samuel L. Jackson Agent
2 102 Samuel L. Jackson Detective
3 103 Samuel L. Jackson Soldier
4 104 Samuel L. Jackson Explorer
5 105 Samuel L. Jackson Vigilante
6 106 Samuel L. Jackson Hitman
7 107 Samuel L. Jackson Runner
8 108 Samuel L. Jackson Hacker
Since it's an inner join, only matching movie_id and cast_id pairs appear in the result.
Index Merge with left_on and right_on
If index names differ between tables, we use left_on and right_on while setting left_index and right_index to True.
movies_to_genres = pd.DataFrame({
"movie_id": [1, 2, 3, 4, 5, 6, 7, 8],
"genre": ["Sci-Fi", "Romance", "Sci-Fi", "Sci-Fi", "Action", "Crime", "Drama", "Sci-Fi"]
}).set_index("movie_id")
merged_df = movies.merge(movies_to_genres,
left_on="id",
right_on="movie_id",
left_index=True,
right_index=True)
print(merged_df)
Output:
title genre
id
1 Inception Sci-Fi
2 Titanic Romance
3 Avatar Sci-Fi
4 Interstellar Sci-Fi
5 The Dark Knight Action
6 Pulp Fiction Crime
7 Forrest Gump Drama
8 The Matrix Sci-Fi
This tells Pandas to match the id index of movies with the movie_id index of movies_to_genres.