Merging Ordered and Time-Series Data
Using merge_ordered()
The merge_ordered() method is used for merging time-series or ordered data. This method merges two tables while maintaining their order and sorting the result. It's similar to the standard merge(), but designed for ordered data like time-series.
- Default join: "outer" (includes all records, fills missing values with NaN).
- Sorted output: Ensures the merged data is in order.
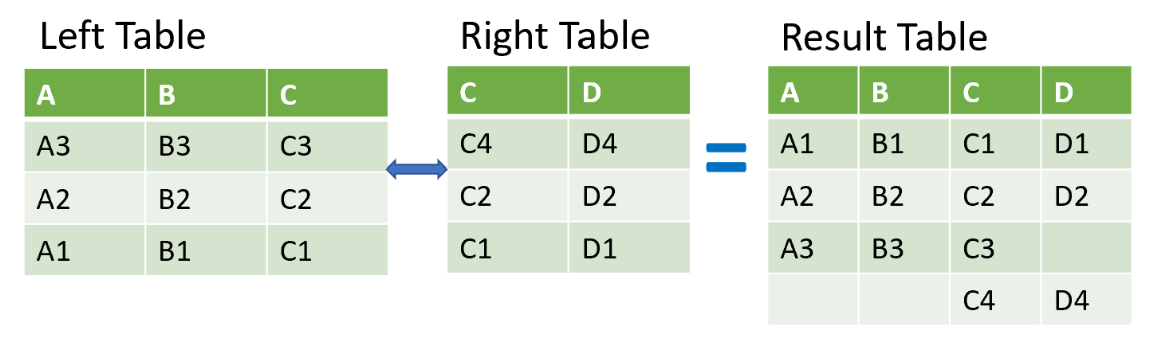
Comparison between merge() and merge_ordered():
| Feature | merge() | merge_ordered() |
|---|---|---|
| Column(s) to Join On | on, left_on, and right_on | on, left_on, and right_on |
| Type of Join | how (left, right, inner, outer) | how (left, right, inner, outer) |
Default: inner | Default: outer | |
| Overlapping Columns | suffixes | suffixes |
| Calling the Method | df1.merge(df2) | pd.merge_ordered(df1, df2) |
Example of merge_ordered()
Consider the stock data for Apple and McDonald's below.
import pandas as pd
# Apple stock data
apple = pd.DataFrame({
'date': ['2007-02-01', '2007-03-01', '2007-04-01'],
'price': [90, 92, 95]
})
# McDonald's stock data
mcd = pd.DataFrame({
'date': ['2007-01-01', '2007-03-01', '2007-05-01'],
'price': [60, 62, 65]
})
To merge the two data:
merged = pd.merge_ordered(apple, mcd, on='date', suffixes=('_apple', '_mcd'))
print(merged)
Output:
date price_apple price_mcd
0 2007-01-01 NaN 60.0
1 2007-02-01 90.0 NaN
2 2007-03-01 92.0 62.0
3 2007-04-01 95.0 NaN
4 2007-05-01 NaN 65.0
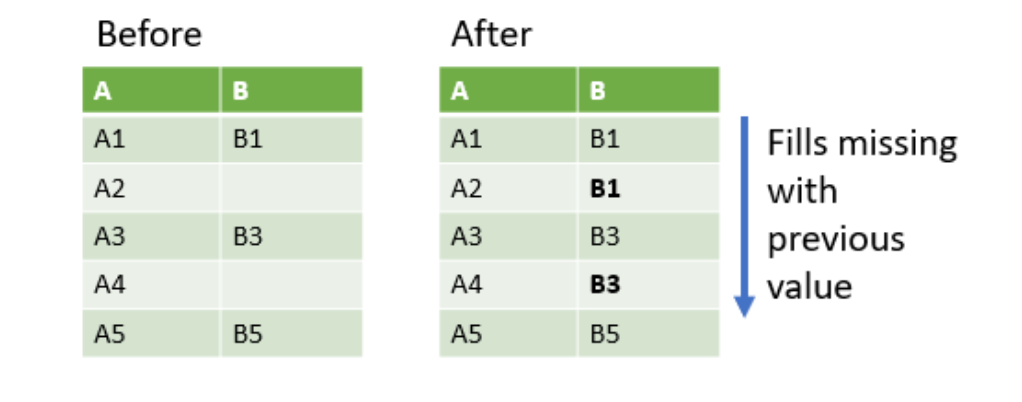
Forward Fill
Missing values can be filled using forward fill ('ffill'), which fills gaps by using the last known value.
merged_ffill = pd.merge_ordered(apple, mcd, on='date',
suffixes=('_apple', '_mcd'),
fill_method='ffill')
print(merged_ffill)
Without forward filling:
date price_apple price_mcd
0 2007-01-01 NaN 60.0
1 2007-02-01 90.0 NaN
2 2007-03-01 92.0 62.0
3 2007-04-01 95.0 NaN
4 2007-05-01 NaN 65.0
After applying forward fill:
date price_apple price_mcd
0 2007-01-01 NaN 60
1 2007-02-01 90.0 60
2 2007-03-01 92.0 62
3 2007-04-01 95.0 62
4 2007-05-01 95.0 65
Notice that the stock price of Apple is still showing NaN because there is no row preceding it.
Using merge_asof()
The merge_asof() method is used to merge tables on the nearest matching values in an ordered dataset. It’s similar to an ordered left join, but instead of matching exact values, it looks for the nearest value.
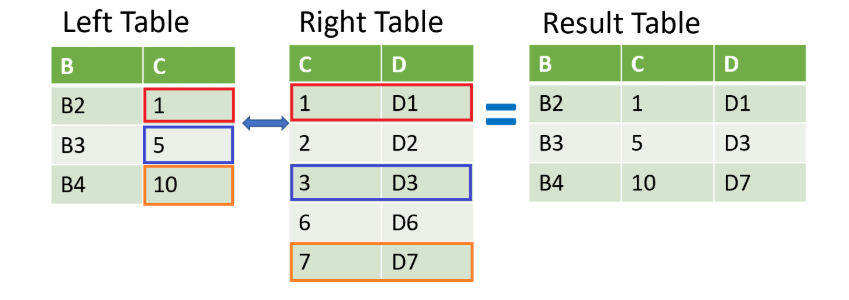
It's useful when you have time-series or ordered data where the exact match might not be available.
- Merges on nearest value, not exact match.
- Requires sorted columns to work properly.
- Useful for time-series data or when values don’t align exactly.
When to Use merge_asof():
- When merging time-series data where exact matches aren't always available.
- When you don’t want to pull future data before the current point in time (like in financial data analysis).
Example of merge_asof()
Consider the stock data for both Visa and IBM below:
import pandas as pd
visa = pd.DataFrame({
'date_time': pd.to_datetime(['2017-11-11 01:45:00', '2017-11-11 02:30:00', '2017-11-11 03:05:00', '2017-11-11 04:50:00']),
'Visa_stock': [100, 105, 110, 115]
})
ibm = pd.DataFrame({
'date_time': pd.to_datetime(['2017-11-11 00:05:00', '2017-11-11 01:15:00', '2017-11-11 03:25:00', '2017-11-11 04:05:00']),
'IBM_stock': [150, 149.11, 151, 152]
})
print(visa)
print(ibm)
Tables:
date_time Visa_stock
0 2017-11-11 01:45:00 100
1 2017-11-11 02:30:00 105
2 2017-11-11 03:05:00 110
3 2017-11-11 04:50:00 115
date_time IBM_stock
0 2017-11-11 00:05:00 150.00
1 2017-11-11 01:15:00 149.11
2 2017-11-11 03:25:00 151.00
3 2017-11-11 04:05:00 152.00
Merge using merge_asof(), specifying date_time as the column to merge on.
result = pd.merge_asof(visa, ibm, on='date_time', suffixes=('_visa', '_ibm'))
print(result)
As we can see, the merge_asof() method selects the IBM stock prices closest to the Visa stock price, but always from a time before or equal to the left table's time.
date_time Visa_stock IBM_stock
0 2017-11-11 01:45:00 100 149.11
1 2017-11-11 02:30:00 105 149.11
2 2017-11-11 03:05:00 110 149.11
3 2017-11-11 04:50:00 115 152.00
Using direction :
You can change the behavior with the direction argument:
| Direction | Description |
|---|---|
| "backward" (default) | Select the closest row from the right table with a value less than or equal to the left table. |
| "forward" | Select the first row in the right table where the value is greater than or equal to the left table. |
| "nearest" | Select the closest row, regardless of whether it's before or after the left table’s row. |
Using direction="forward":
result_forward = pd.merge_asof(visa, ibm, on='date_time', direction='forward')
print(result_forward)
Here, the forward direction picks the next available IBM price that’s greater than or equal to the Visa time.
date_time Visa_stock IBM_stock
0 2017-11-11 01:45:00 100 151.0
1 2017-11-11 02:30:00 105 151.0
2 2017-11-11 03:05:00 110 151.0
3 2017-11-11 04:50:00 115 NaN
Selecting wth .query()
The .query() method in pandas is a simple way to filter rows in a DataFrame using string-based conditions. It's similar to SQL's WHERE clause but does not require SQL knowledge.
- Takes a string condition to filter rows
- Works similarly to SQL but is simpler
- Supports numerical and text-based conditions
Example: Selecting rows where Nike's stock price is 90 or higher.
| Date | Disney | Nike |
|---|---|---|
| 2023-01-01 | 135 | 88 |
| 2023-01-02 | 138 | 92 |
| 2023-01-03 | 140 | 97 |
| 2023-01-04 | 142 | 89 |
| 2023-01-05 | 137 | 91 |
Importing the data:
import pandas as pd
stocks = pd.DataFrame({
"Date": ["2023-01-01", "2023-01-02", "2023-01-03", "2023-01-04", "2023-01-05"],
"Disney": [135, 138, 140, 142, 137],
"Nike": [88, 92, 97, 89, 91]
})
Running the queries:
-
Query 1: Select rows where Nike is 90 or higher
result1 = stocks.query("Nike >= 90")print("Query 1 Output:\n", result1, "\n")Output:
Date Disney Nike1 2023-01-02 138 922 2023-01-03 140 974 2023-01-05 137 91 -
Query 2: Select rows where Nike is over 90 AND Disney is below 140
result2 = stocks.query("Nike > 90 and Disney < 140")print(result2)Output:
Date Disney Nike1 2023-01-02 138 924 2023-01-05 137 91 -
Query 3: Select rows where Nike is over 96 OR Disney is below 98
result3 = stocks.query("Nike > 96 or Disney < 98")print(result3)Output:
Date Disney Nike2 2023-01-03 140 97
Updating the sample data with stocks_updated, adding text values:
stocks_updated = pd.DataFrame({
"Date": ["2023-01-01", "2023-01-02", "2023-01-03", "2023-01-04", "2023-01-05"],
"Stock": ["Disney", "Nike", "Nike", "Disney", "Nike"],
"Close": [135, 92, 89, 142, 87]
})
print(stocks_updated)
Output:
Date Stock Close
0 2023-01-01 Disney 135
1 2023-01-02 Nike 92
2 2023-01-03 Nike 89
3 2023-01-04 Disney 142
4 2023-01-05 Nike 87
To select rows where Stock is "Disney" OR Stock is "Nike" AND Close is below 90
result4 = stocks_updated.query('Stock == "Disney" or (Stock == "Nike" and Close < 90)')
print(result4)
Output:
Date Stock Close
0 2023-01-01 Disney 135
2 2023-01-03 Nike 89
3 2023-01-04 Disney 142
4 2023-01-05 Nike 87