Data Quality
Updated May 12, 2023 ·
Overview
This design phase checks data quality and decides how to collect and process it. Data quality measures how well data serves its purpose.
- Poor data leads to inaccurate predictions.
- Evaluated using accuracy, completeness, consistency, and timeliness.
Data Quality Dimensions
A good dataset should meet the following criteria:
| Metric | Description | Example |
|---|---|---|
| Accuracy | Data should reflect reality | A customer’s age recorded as 18 when they are actually 32 |
| Completeness | Missing data should be minimal | A customer’s last name is missing |
| Consistency | Data should be uniform across sources | The customer is marked active in one database but inactive in another. |
| Timeliness | Data should be available when needed | Orders sync at the end of the day but are not available in real-time. |
If data quality is low in one or more dimension, we can:
- Collect more data
- Fill missing values
- Standardize definitions
Data Ingestion
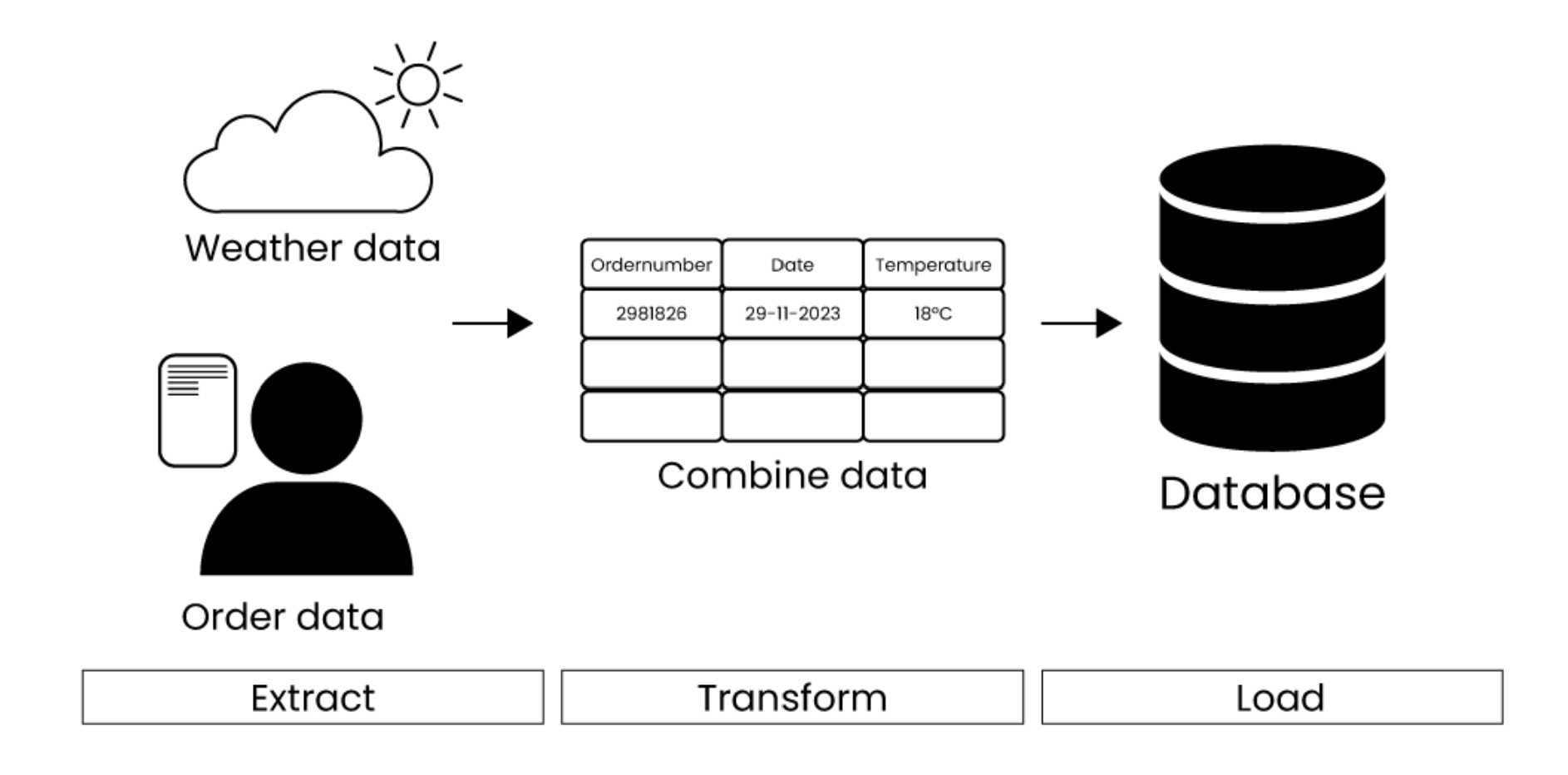
Once we have quality data, we need a way to collect and process it. Automated data pipelines help extract, process, and store data efficiently using the ETL process:
- Extract: Get data from sources.
- Transform: Convert it into the right format.
- Load: Store it in a database.