Deployment
Overview
Before deploying a machine learning model, we need to ensure it runs smoothly in production. This includes managing different runtime environments and using containers for consistency.
Dev vs Prod
Models go through different stages before deployment.
| Stage | Description |
|---|---|
| Development | Models are trained using sample data on a local machine or cloud |
| Production | Deployed models process real-world data and make real-time predictions |
Before full deployment, models may also run in a testing environment to identify and fix issues. However, differences in runtime environments can still cause problems.
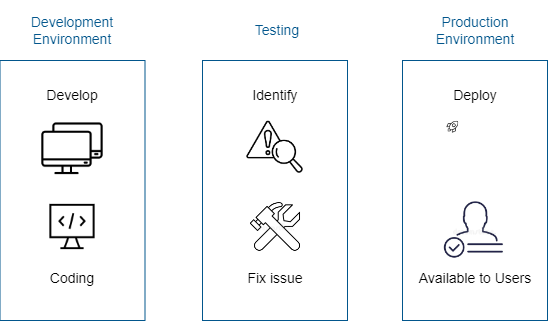
Runtime Environments
Development and production environments may have different software setups, which can lead to errors or performance issues.
- Different Python versions, libraries, or dependencies can break the model.
- Hardware, operating systems, or resource limitations may affect speed and accuracy.
To solve this, we use containers.
Using Containers
A container packages a program with all its dependencies to ensure consistent performance across environments.
- Works the same across different environments.
- Build once, run anywhere.
- Starts quickly with only necessary components.
For more information, please see Containerization.
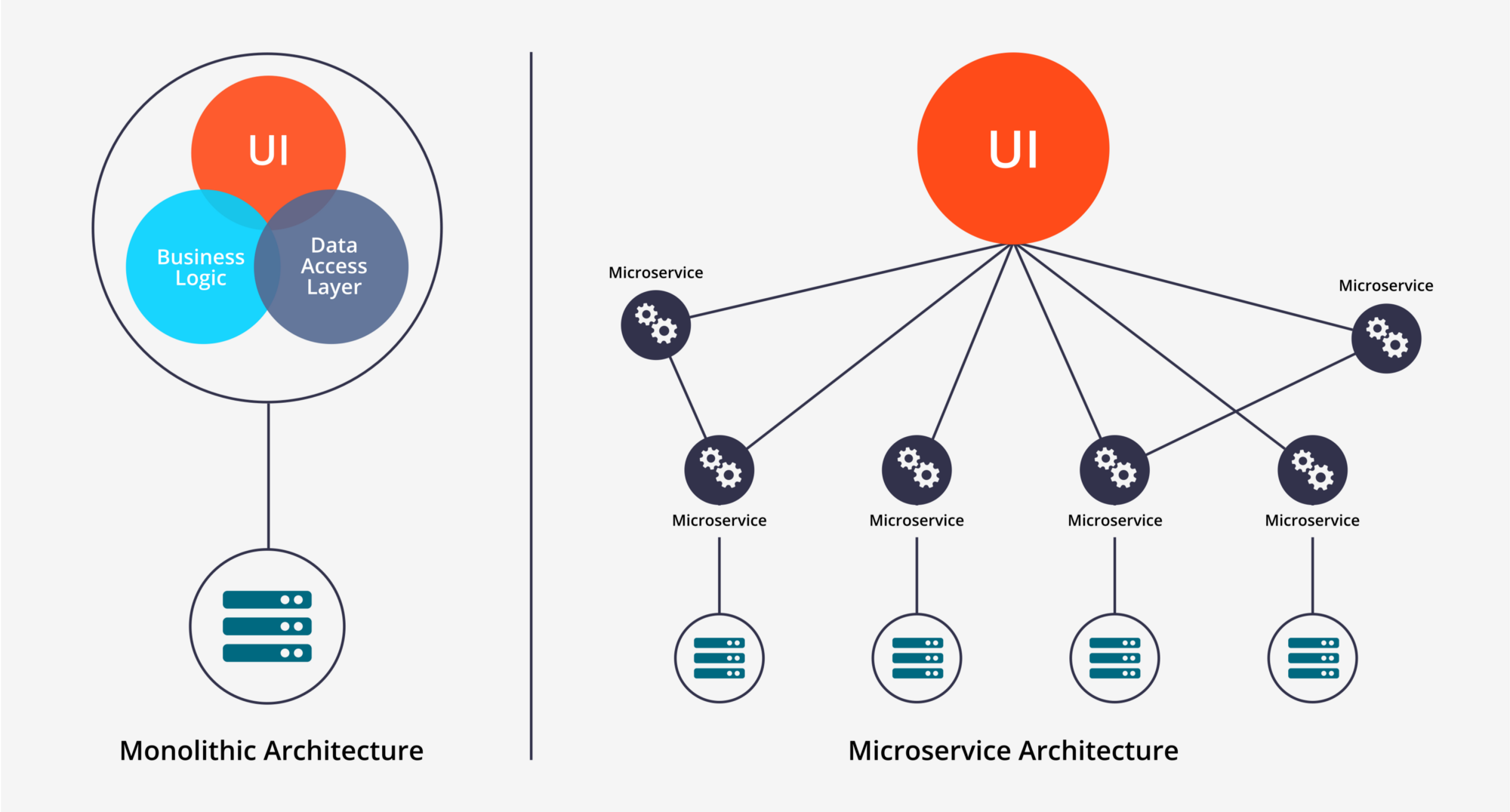
Microservices Architecture
Before deploying a machine learning model, we need to decide how to structure the system. This involves choosing between a monolithic or microservices architecture.
| Type | Description |
|---|---|
| Monolith | All services run as a single application |
| Microservices | Services are independent and deployed separately |
A monolithic system can become complex and difficult to scale because all parts are tightly connected. If one part fails, the whole system may go down. On the other hand, microservices allow individual services to fail without affecting the entire system, making them more flexible. However, they require more resources and maintenance.
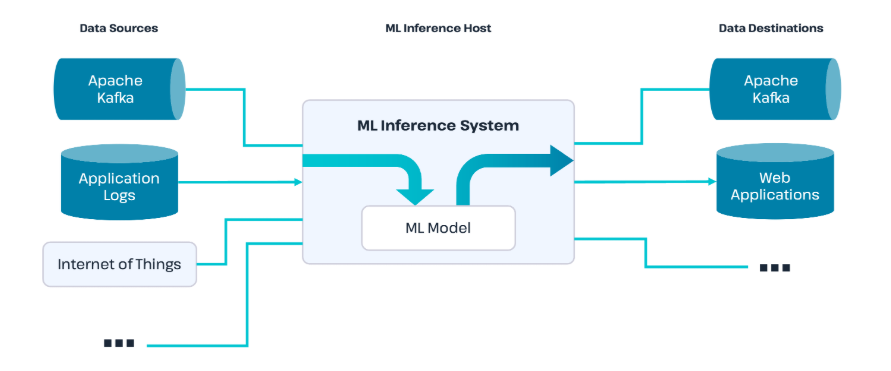
Inferencing
Machine learning models are often deployed as microservices, allowing them to process new data and make predictions independently. This process, called inferencing, involves sending input, like customer data, to the model and receiving an output, such as the likelihood of a customer churning.
APIs for Communication
Microservices rely on APIs to communicate and define how they interact with each other.
- With API: Think of an API like a bridge between two islands, allowing information to travel back and forth.
- Without an API: Without this bridge, services can't exchange information properly, leading to confusion and errors.
Using APIs ensures that services can communicate clearly and work together efficiently.
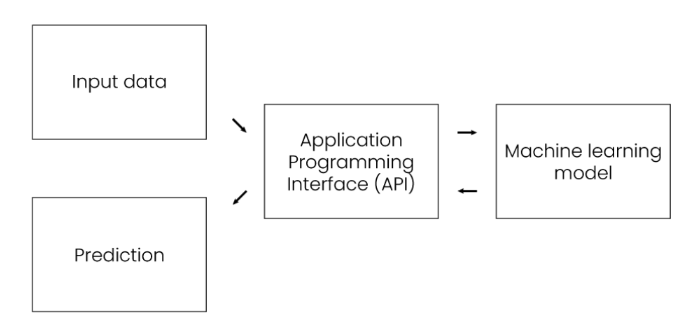
Here’s an example of how an API request works with a machine learning model:
- New input data is received.
- The data is sent to the API.
- The API forwards the data to the machine learning model.
- The model generates a prediction based on the data.
- The prediction is sent back to the API.
- The API sends the prediction to the application.