Parsing with Grok
Structured and Unstructured Data
Structured data is highly organized and stored in a predefined format like rows and columns, making it easy to search, analyze, and process. Logstash can efficiently parse this type of data and transform it for indexing in Elasticsearch or other destinations.
For example, consider the following CSV file.
id,name,email
1,John Doe,johndoe@example.com
2,Jane Smith,janesmith@example.com
3,Bob Johnson,bobjohnson@example.com
This file contains three fields.
id(unique identifier)name(full name of the individual)email(contact email)
The structure allows straightforward processing and data extraction.
On the other hand, unstructured data lacks a predefined format, which makes it harder to organize and process. Examples include text logs, emails, or multimedia files that require advanced parsing techniques. Parsing unstructured data can be complex due to inconsistent formats or mixed information types.
For instance, Linux system logs like the following:
Dec 31 10:12:45 localhost kernel: [ 1234.567890] CPU: 2 PID: 1234 Comm: bash Not tainted
Dec 31 10:12:46 localhost sshd[5678]: Accepted password for user from 192.168.1.100 port 22 ssh2
Dec 31 10:12:47 localhost systemd[1]: Started Session c1 of user root.
These logs are a mix of timestamps, system events, and metadata. Parsing such logs requires tools capable of handling inconsistent formats and extracting key details like timestamps, process IDs, or event descriptions.
Grokking
Grok filtering is a powerful feature in Logstash that allows extracting and structuring unstructured data. It uses patterns to match and parse specific fields from logs or text data for easier processing.
- Simplifies parsing of complex log files.
- Helps structure unorganized data for indexing and analysis.
Grok uses regular expressions (regex) to identify patterns in text. It includes prebuilt patterns for common log types, making it versatile for processing diverse data formats.
As an example, let's say we want a regex pattern to match the following email addresses:
john@xyz.com
ted2024@abc.edu
abby21street@gov.au
The regex to match these email addresses:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
Predefined Grok Patterns
Grok includes predefined patterns that simplify the parsing of common data formats, such as emails, IP addresses, or timestamps. These patterns save time and make it easy to extract structured data from unstructured logs.
- Predefined patterns cover a wide range of use cases
- Easy to use and customize for specific fields in log data.
For example, to extract an email address from a log:
%{EMAILADDRESS:client_email}
For more information, please see Grokking grok.
Generic Grok Syntax
The Grok syntax uses a standard format to match and extract data from logs. Each Grok expression is composed of patterns and identifiers to capture specific fields.
%{PATTERN:identifier}
Using Grok
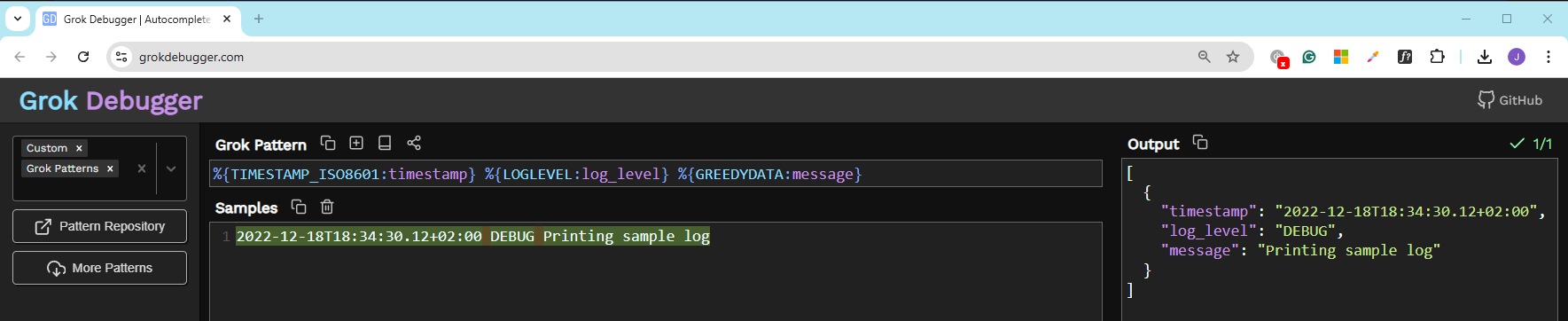
Consider the sample log below. This log is in ISO format, commonly used for timestamps.
2022-12-18T18:34:30.12+02:00 DEBUG Printing sample log
This line has three components:
-
Timestamp: Represents the log's creation time.
%{TIMESTAMP_ISO8601:timestamp} -
Log Level: Indicates the log's severity or type.
%{LOGLEVEL:log_level} -
Message: Contains the details of the log entry.
%{GREEDYDATA:message}
To extract these components, the Grok filter can be written as:
%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log_level} %{GREEDYDATA:message}
Testing Grok Patterns
We can use the Grok Debug Tool to test and refine Grok patterns.
- Input the sample log and the Grok pattern.
- Enable the "Named Captures Only" option to see only the extracted fields.
Using the previous example, we can enter the sample log and the pattern.