Flattened Data Type
Overview
When dealing with deeply nested or highly dynamic fields in Elasticsearch, you may encounter mapping explosion, where the number of fields in the mapping grows excessively. This can lead to performance issues and make the mapping difficult to manage.
Cluster Mappings
Download the dataset below:
First, store the Elasticsearch endpoint and credentials in variables:
ELASTIC_ENDPOINT="https://your-elasticsearch-endpoint"
ELASTIC_USER="your-username"
ELASTIC_PW="your-password"
Index the dataset from the demo-default.json file into the Elasticsearch.
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT "$ELASTIC_ENDPOINT:9200/demo-default/_doc/1" \
-d @demo-default.json | jq
Output:
{
"_index": "demo-default",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
Next, you can check the mappings of the demo-default index:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XGET "$ELASTIC_ENDPOINT:9200/demo-default/_mapping?pretty=true" | jq
The returned output shows the automatically assigned field types by Elasticsearch for each field. We didn’t explicitly define any field types, but Elasticsearch inferred the types based on the data provided.
{
"demo-default": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"fileset": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"host": {
"properties": {
"hostname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"process": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"pid": {
"type": "long"
}
}
}
}
}
}
}
Cluster State
You can check the state of the Elasticsearch cluster using the following command:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XGET "$ELASTIC_ENDPOINT:9200/_cluster/state?pretty=true" | jq >> es-cluster-state.json
As a recap, an Elasticsearch cluster consists of a master node that sends the latest cluster state to all other nodes. When a node receives the updated state, it acknowledges the master node.
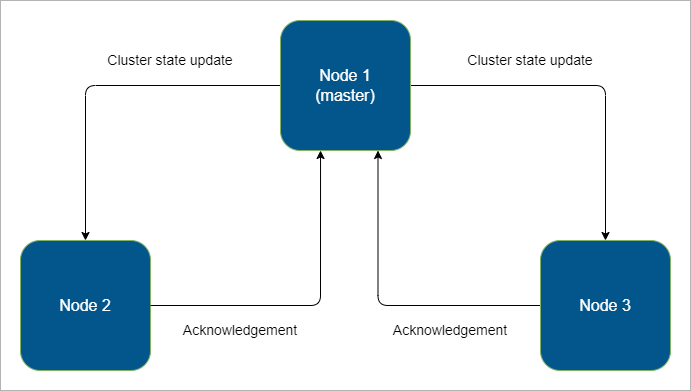
When new fields are added to documents, Elasticsearch creates new mappings, which also update the cluster state. Regularly adding fields can cause the cluster state to grow, leading to delays and performance issues.
Too many fields in the mapping can result in a mapping explosion, which can then impact memory and overall cluster performance. To prevent mapping explosions, Elasticsearch introduces the flattened datatype.
Using Flattened Data Type
The flattened data type allows us to index complex, nested JSON objects while keeping the data structure flat.
- Flattens complex data for easier querying.
- Reduces mapping complexity and improves query performance.
Example: Creating and Mapping the Index
First, create the index demo-flattened:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT $ELASTIC_ENDPOINT:9200/demo-flattened | jq
Output:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "demo-flattened"
}
Next, define the mapping for the host field as a flattened type:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT "$ELASTIC_ENDPOINT:9200/demo-flattened/_mapping" -d '{
"properties": {
"host": {
"type": "flattened"
}
}
}' | jq
Indexing the Dataset
Now, index the same demo-default.json file from the previous example into the demo-flattened index:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT "$ELASTIC_ENDPOINT:9200/demo-flattened/_doc/1" \
-d @demo-default.json | jq
Output;
{
"_index": "demo-flattened",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
Checking the Mapping
To verify the mapping of the host field, run the following command:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XGET "$ELASTIC_ENDPOINT:9200/demo-flattened/_mapping?pretty=true" | jq
You should see the following for the host field:
"host": {
"type": "flattened"
},
Adding Inner Fields to the Flattened Field
Next, let's add new inner fields to the host field:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-X POST "$ELASTIC_ENDPOINT:9200/demo-flattened/_update/1" -d '{
"doc": {
"host": {
"osVersion": "Bionic Beaver",
"osArchitecture": "x86_64"
}
}
}' | jq
You would expect the inner fields to be added to the mapping. However, because the host field is defined as a flattened type, Elasticsearch will not automatically add these new fields to the mapping.
To confirm this, check the mapping again:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XGET "$ELASTIC_ENDPOINT:9200/demo-flattened/_mapping?pretty=true" | jq
As seen below, the flattened data type does not dynamically add new fields to the mapping when inner fields are added. This is a limitation of the flattened type, but this also significantly reduces the size of the mapping and reduces the risk of mapping explosions.
"host": {
"type": "flattened"
},
Limitations
The main limitation of the flattened data type is that fields are treated as keywords, meaning no analyzers or tokenizers are applied. This limits the search capability because:
- Only exact matches are supported, not partial or full-text search.
- Fields aren't tokenized, so complex searches or custom parsing aren't possible.
While flattened fields are great for structured data, they are not ideal for full-text search or complex text processing.
To demonstrate the limitation, run a query on a flattened field from the previous example:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XGET "$ELASTIC_ENDPOINT:9200/demo-flattened/_search?pretty=true" -d'
{
"query": {
"term": {
"host.osVersion": "Beaver"
}
}
}' | jq
The response shows that since the field is flattened, it doesn't allow partial search or text matching:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
Supported Queries
Below are supported queries for the flattened data type:
| Query Type | Description |
|---|---|
term, terms, and terms_set | Exact matches against the field values. |
prefix | Finds documents where the field value starts with a specified prefix. |
range | Supports non-numerical range operations (e.g., matching string values). |
match and multi_match | Exact keyword matches (not for full-text searches). |
query_string and simple_query_string | Allows for complex search expressions with exact keyword matches. |
exists | Checks if a specific field exists within the document. |