Data Modelling
Overview
Data modeling in Elasticsearch organizes and optimizes data for efficient storage and faster retrieval. Proper modeling ensures scalability and improves query performance.
The parent-child relationship is a key feature that links related documents without storing redundant data.
- Related data is stored in distinct documents, reducing duplication.
- Retrieval of related data using efficient parent-child queries.
Normalized Data
Normalized data reduces redundancy by dividing information into smaller, related documents. This approach optimizes storage and ensures data consistency.
- Reduces duplication, saving storage space
- Requires joins or multiple queries to retrieve related data
Consider the diagram below.
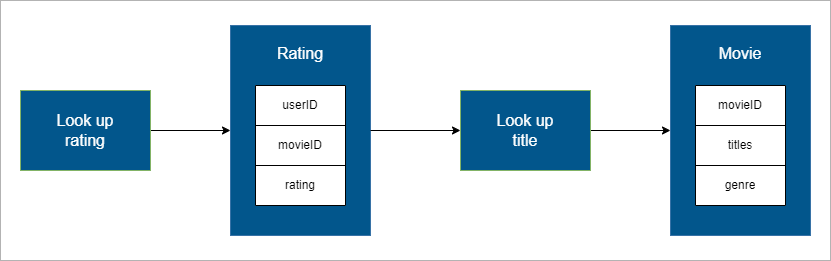
This diagram shows how normalized data minimizes duplication:
- Ratings are stored in a separate table with userID, movieID, and rating.
- Movie details like title and genres are stored in another table.
- Retrieving data requires looking up ratings and titles separately.
This structure makes it easy to update titles but requires multiple queries to fetch related information.
For more details, please refer to the Normalization Guide.
Denormalized Data
Denormalized data combines related information into a single document for faster access. This approach simplifies queries but increases storage needs.
- Stores all necessary data together, speeding up queries
- Increases storage usage due to repeated data
Using the previous example, the title is included in every rating record. This allows retrieving both the rating and title in one query.

As shown, titles are duplicated, which uses more storage space, but the benefit is that all required information can be retrieved in a single query.
Parent-Child Relationship
In Elasticsearch, parent-child relationships allow related documents to be stored separately while maintaining a connection between them. This approach is useful for scenarios where data is hierarchical or frequently updated.
- Enables storing parent and child documents independently
- Allows child documents to be updated without reindexing the parent
- Supports complex queries that link parent and child data efficiently
Movie Franchises
In this example, we'll create a mapping for movie franchises and establish the parent-child relationship with the movies that belong to each franchise.
The example below is tested on a running Elasticsearch 8 cluster. You also need to install jq on the node.
Step 1: Create the Mapping
First, store the Elasticsearch endpoint and credentials in variables:
ELASTIC_ENDPOINT="https://your-elasticsearch-endpoint"
ELASTIC_USER="your-username"
ELASTIC_PW="your-password"
Start by creating the mapping for the series index with a join field that will support the parent-child relationship between franchises and films:
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT $ELASTIC_ENDPOINT:9200/series -d '
{
"mappings": {
"properties": {
"film_franchise": {
"type": "join",
"relations": {
"franchise": "film"
}
}
}
}
}' | jq
Output:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "series"
}
Step 2: Download and Populate the Dataset
Download the dataset below:
Populate the index with the dataset using the command below.
curl -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-XPUT $ELASTIC_ENDPOINT:9200/_bulk?pretty \
--data-binary @series.json
Step 3: Search for Movies Belonging to the "Star Wars" Franchise
Now that the data is indexed, we can search for all movies belonging to the Star Wars franchise using the has_parent query.
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-X GET "$ELASTIC_ENDPOINT:9200/series/_search?pretty" -d '{
"query": {
"has_parent": {
"parent_type": "franchise",
"query": {
"match": {
"title": "Star Wars"
}
}
}
}
}' | jq
It will return...
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 7,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "series",
"_id": "260",
"_score": 1,
"_routing": "1",
"_source": {
"id": "260",
"film_franchise": {
"name": "film",
"parent": "1"
},
"title": "Star Wars: Episode IV - A New Hope",
"year": "1977",
"genre": [
"Action",
"Adventure",
"Sci-Fi"
]
}
},
....
....
....
{
"_index": "series",
"_id": "122886",
"_score": 1,
"_routing": "1",
"_source": {
"id": "122886",
"film_franchise": {
"name": "film",
"parent": "1"
},
"title": "Star Wars: Episode VII - The Force Awakens",
"year": "2015",
"genre": [
"Action",
"Adventure",
"Fantasy",
"Sci-Fi",
"IMAX"
]
}
}
]
}
}
Step 4: Find the Franchise Associated with a Given Film
You can also reverse the query to find the franchise associated with a specific film. For example, searching for the franchise associated with "A New Hope":
curl -s -u $ELASTIC_USER:$ELASTIC_PW \
-H 'Content-Type: application/json' \
-X GET "$ELASTIC_ENDPOINT:9200/series/_search?pretty" -d '{
"query": {
"has_child": {
"type": "film",
"query": {
"match": {
"title": "A New Hope"
}
}
}
}
}' | jq
It will return...
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "series",
"_id": "1",
"_score": 1,
"_routing": "1",
"_source": {
"id": "1",
"film_franchise": {
"name": "franchise"
},
"title": "Star Wars"
}
}
]
}
}