HA and DR
Capacity Planning
Capacity planning involves determining the resources (such as staff, equipment, and systems) needed to maintain essential business operations during a disruption or disaster.
-
People
- Analyze current skills of the members.
- Forecast ftuture needs for hiring or training.
- Right number of people with right skills.
-
Technology
- Assessing current resources and utilization.
- Anticipating future needs; evaluate if current technology can accomodate future growth.
-
Infrastructure
- Considering physical space and utilities to support organizational needs.
- Office spaces, warehouses, production facilities, datacenters.
-
Processes
- Optimize business processes to handle demand fluctuations.
- Fluctuations can be increase or decrease in demand.
- Enhance workflow, efficiency through automation, or outsourcing througb third-party vendor.
High Availability
The ability of a service to be continuously available by minimizing downtime to the lowest amount possible.
Fault tolerance describes the ability of a system to continue operation even when one of the components fails so that there is no downtime.
High availability is similar, but simply describes that a system should be available as much as possible, though there may be some minimal downtime.
Uptime
The number of minutes or hours that a system remains online over a given period.
- Usually expressed in percentage
- Gold standard - five nines or "99.999"
- 99.999% uptime means only 5 minutes downtime in one year.
Load Balancing
The process of balancing workloads across multiple computing resources.
- Provide high availability by redirecting traffic during server failures.
- Balance loads based on various algorithms, such as round-robin or least connections.
- Improve response times and optimize resource usage.
For more information, please see LoadBalancers.
Clustering
Multiple computers and multiple storage devices are grouped together to work as a single system.
- Redundant connections.
- Ensure no single point of failure by providing redundancy.
- Provide high levels of availability, reliability, and scalability.
- Can be combined with loadbalancing.
Disaster Recovery
The Goal of Disaster Recovery
Disaster recovery capabilities are designed to restore business to normal operations as quickly as possible.
- Initial response is to contain the damage caused by the disaster.
- Recover whatever capacity may be immediately restored.
- Activities may vary widely depending upon the nature of the disaster.
During disaster recovery efforts, the focus shifts from normal business activity to a concentrated effort to restore operations.
- Employee responsibilities may change temporarily.
- Flexibility is key during a disaster response.
- Organizations should plan out responsibilities in advance.
- Employees should be provided training in advance.
After the immediate danger passes, the team shifts to assessment mode. The goal of this phase is to triage the damage to the organization and develop a plan to recover operations on a permanent basis.
Disaster Recovery efforts only end when the business is back to operating normally in its primary facility.
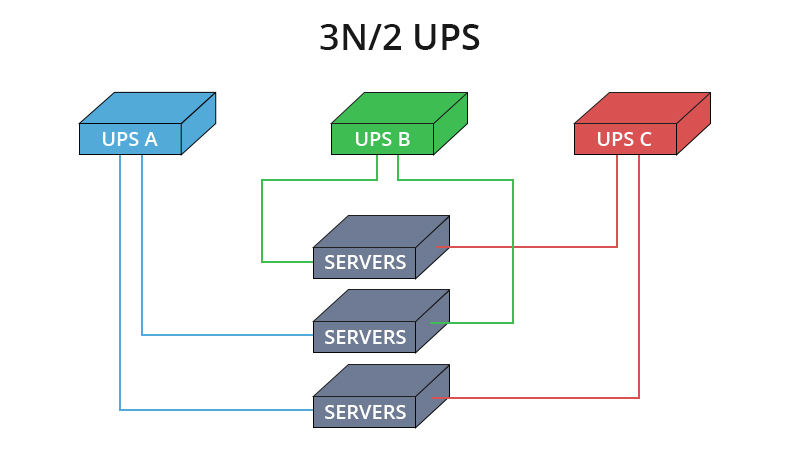
Redundancy
Design systems with duplicate components for backup in case of failure.
- Assess the need for multiple utility service entrances for redundant communication.
- Aim for full redundancy with devices having two power supplies from diverse sources.
- Backup power sources include batteries and generators.
- In high-availability environments, generators should be redundant and fueled by different sources.
Failover
Failover involves establishing an alternate location, such as a secondary data center or cloud infrastructure, where critical business functions can continue in case the primary site becomes unavailable due to a disaster or incident.
Disaster Recovery Sites
-
Hot Site
- Fully operational duplicate of the primary site.
- Quickest switchover time, but most expensive.
- Real-time data replication for immediate takeover.
-
Warm Site
- Has necessary systems but lacks current data for immediate operations.
- Longer switchover but less expensive
- Hardware and connectivity are in place.
- Data is restored from backups, which may not be up-to-date.
- Example: A financial services company with a warm site in another city.
-
Cold Site
- Basic facility with power and cooling.
- Requires significant time to become operational.
- No hardware, software, data, personnel
- Longest switchover, but cheapest option.
-
Mobile Site
- Can be a hot site, warm site, or a cold site.
- Utilizes independent and portable units like trailers or tents.
- Self-sufficient, contains everything you need.
- Deployed to places that needs recovery quick.
-
Virtual Site
-
Utilized cloud-based environments.
-
Offers highly flexible approach to redundancy.
-
Examples:
Site Type Description Virtual Hot Site Fully replicated and instantly accessible Virtual Warm Site Partially replicated and scalable Virtual Cold Site Minimal activation to minimize costs
-
Disaster Recovery Tests
-
Read-through Exercises
- Simplest form of DR test, also known as checklist reviews
- Each team member reviews their roles in the DR process
- Personnel provides feedbacks about any updates needed
- Assess procedures/protocols, not technical recovery aspects
-
Tabletop Exercises
- Also known as walk-throughs
- Involves getting everyone aroung the same table
- Same results as read-throughs, but more effective
- Focus on procedures and protocols, not technical recovery
- Scenario-based discussion where team plans responses
- Least impact, does not involve actual disruption
-
Simulation Exercise
- Computer-based representations of real-world scenarios
- Theoretical, low impact, to gather all possible response
- Provides a realistic scenario to test incident handling
-
Failover Test
- Verifies transition to a backup in the event of failure
- Require more resources, but verifies that the plan works
-
Parallel Test
- Runs primary and alternate sites together.
- Activates the DR plan, brings up a hot or warm site.
- Primary continues operations, alternate processes backup transactions.
- Least disruptive, but time-consuming among recovery tests.
-
Full Interruption Test
- Most effective test, but also has most impact to operations
- Shuts down primary site, relies entirely on the alternate site.
- More disruptive and costly compared to a parallel test.
Disaster Recovery Plan (DRP)
Organizations typically prepare a variety of documents as part of their Disaster Recovery Planning (DRP) to meet the needs of different audiences. These include:
| Document Type | Description |
|---|---|
| Executive summary | High-level plan overview |
| Department-specific plans | Tailored for different organizational units |
| Technical guides | For IT personnel handling critical backups |
| Full plan copies | For critical disaster recovery team members |
Roles involved:
- Disaster recovery team members
- IT personnel
- Managers and public relations personnel
When creating your Disaster Recovery Plan (DRP), include steps to recover PKI-encrypted files linked to damaged user accounts. In a PKI system, each user has two keys: a public key to encrypt data and a private key to decrypt it. The private key is kept safe in places like certificates, directories, or smart cards.
BC vs DR
-
Business Continuity (BC) plans
- Emphasizes proactive strategies to prevent or minimize disruptions.
- Ensures critical business functions continue without interruption.
- For more details, see Business Continuity.
-
Disaster Recovery (DR) plans
- Restores IT systems, apps, and data after a disruption.
- Step-by-step procedures to recover operations quickly and efficiently.
- Often includes backup systems, failover processes, and recovery priorities.