Automated Tracking
Updated May 15, 2023 ·
ML is Experimental
Machinge Learning is experimental in nature and it involves trial and error. Engineers test different approaches to find the best model.
- Modify data sources (e.g., applying transformations)
- Train models with different algorithms
- Choose evaluation metrics to compare performance
Since there are too many possibilities, manually tracking every experiment is impractical.
Problems Without Automation
Without automated tracking, ML workflows become chaotic.
- Hard to track experiments and results
- Difficult to reproduce and share findings
- Wasted time and resources
Logging
Logging requirements depend on the project. Common elements include:
| Component | Description |
|---|---|
| Code | Version of scripts used |
| Configuration | Experiment settings and environment details |
| Data | Source, type, format, preprocessing steps |
| Model | Parameters, hyperparameters, and evaluation metrics |
Benefits:
| Benefit | Description |
|---|---|
| Reproducibility | Others can verify and rerun experiments |
| Performance tracking | Compare models and improve results |
| Transparency | Understand decisions and detect issues |
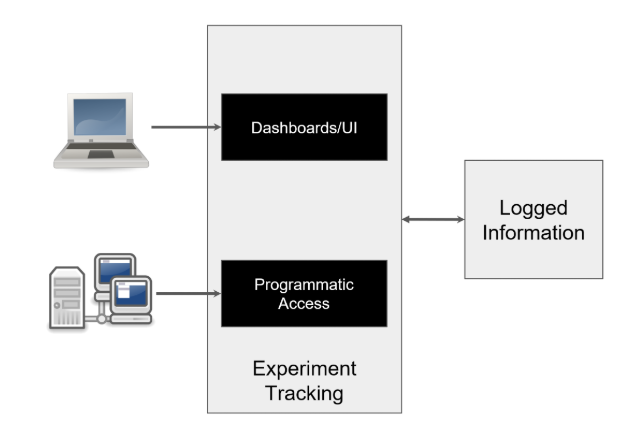
Automated Tracking Systems
Automated Tracking Systems organize and display logged data.
- View training metadata and compare runs
- Track and reproduce experiments
- Access via dashboards or programmatic interfaces
- Promote top models to the model registry
Available Tools
Building a tracking system from scratch is complex. There aree options that exists in the market:
- Open-source: MLflow, Weights & Biases, Sacred
- Paid solutions: Azure ML, Google Vertex AI, AWS SageMaker
Choosing the right tool depends on budget and requirements.