Reference Architecture
Overview
A reference architecture provides structures and patterns to streamline development, minimize technical debt, and create scalable, maintainable ML solutions.
- Blueprint for IT solutions.
- Uses best practices and patterns.
- Helps in creating repeatable, scalable systems.
Adopting a reference architecture ensures the ML system follows proven practices and maintains high quality throughout its lifecycle.
Fully Automated
A fully automated MLOps architecture helps automate the entire ML pipeline, and ensures faster and more efficient model deployment. It includes the following:
- CI/CD pipelines for continuous integration.
- Continuous monitoring of models.
- Continuous training for model updates.
This architecture makes it easy to deploy and monitor models, and improves overall efficiency.
Reference: MLOps level 2: CI/CD pipeline automation
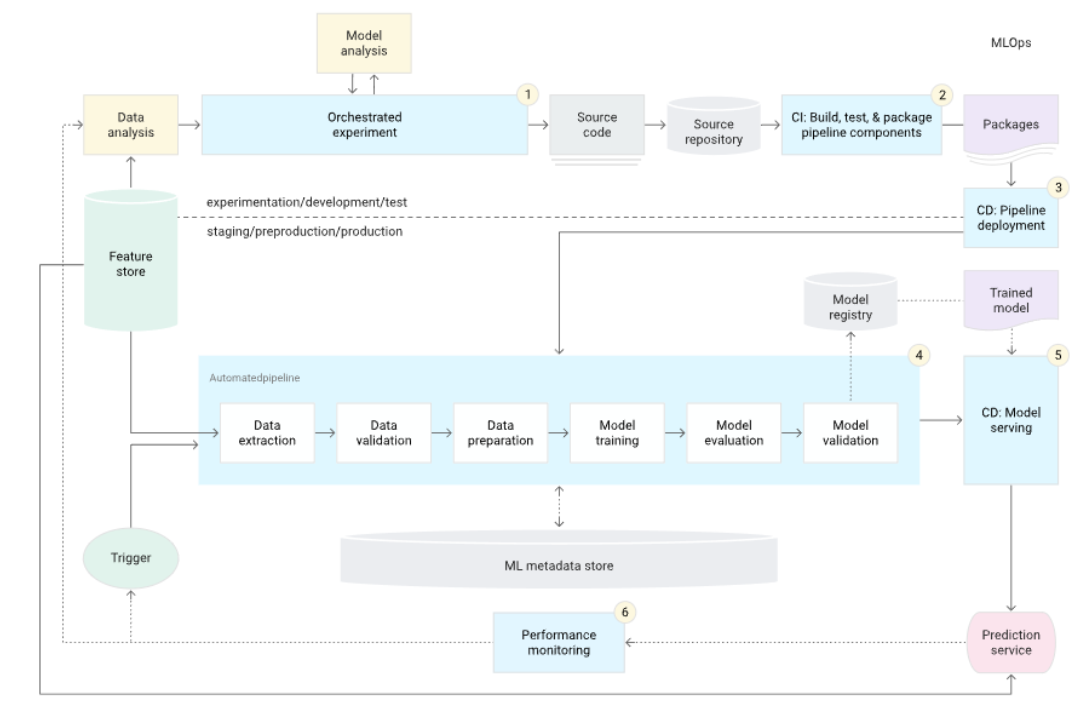
Orchestrated Experiments
The first step in the architecture involves orchestrating ML experiments in the development environment.
- Executes pre-defined ML experiments.
- Helps in efficient model testing and iteration.
This step allows systematic exploration of model variations and performance tuning.
Source Code & Continuous Integration (CI)
In the next phase, source code is pushed to a repository where it’s stored and managed. The CI process builds and tests the code.
- Source code management.
- Automated testing and building.
CI ensures that every change is tested, and ensures stability and quality throughout development. This stage produces artifacts such as packages and executables.
Artifacts & Continuous Delivery (CD)
Artifacts from the CI stage are deployed to the production environment via CD.
- CI artifacts are deployed automatically.
- Continuous deployment to production.
This stage automates the deployment of tested code to production, speeding up the release process.
ML Pipeline Deployment
Once the artifacts are in production, the automated ML pipeline is deployed with the new model implementation.
- New model implementation.
- Automated ML pipeline deployment.
This step ensures that the latest models are constantly being deployed with minimal manual intervention.
Metadata Store
A metadata store keeps track of all the data and logs generated throughout the ML pipeline, such as hyperparameters and execution logs.
- Stores model training data.
- Logs pipeline execution details.
For more information, please see Metadata Store.
Model Registry
Models produced by the pipeline are stored in a model registry for easy tracking and management.
- Stores versions of models.
- Facilitates model tracking.
This registry helps manage and access different versions of models in a structured way.
Prediction Services
After models are deployed, prediction services are continuously updated and delivered automatically.
- Continuous delivery of new models.
- Automatic prediction service updates.
This ensures the latest models are always in use for predictions, improving decision-making.
Continuous Monitoring
The performance of models is continuously monitored to gather insights into their effectiveness.
- Tracks model performance.
- Collects statistics for analysis.
Monitoring helps identify any issues or areas for improvement in the deployed models.
Automated Trigger
Model performance data can trigger the re-execution of the ML pipeline automatically.
- Uses performance stats to trigger pipeline.
- Automated execution of training processes.
This ensures that the model stays up-to-date based on real-world performance.
Automated Retraining
When triggered, the pipeline starts retraining a new model. It can also activate fallback mechanisms, like using backup models if needed.
- Retrains models automatically.
- Fallback mechanisms in case of failure.
This keeps the model relevant and accurate over time, minimizing errors in production.
Feature Store
The feature store ensures that the features used in the ML system are consistent, reusable, and reproducible across different stages of the pipeline.
For more information, please see Feature Store.