Schemas and Normalization
Overview
The star schema is a basic form of dimensional modeling that uses fact and dimension tables. Some use both the terms "dimensional modeling" and "Star schema" interchangeably. The star schema is made up of two tables:
- Fact tables: Hold metrics and change often, with foreign keys to dimension tables.
- Dimension tables: Describe attributes, changing less frequently.
In a bookstore example, the start schema can be used to track book sales across the US and Canada.
- Fact tables store sales data such as sales amount and quantity.
- Dimension tables provide details on books, sales time, and stores.
- Structure looks like a star with one-to-many relationships.
Star Schema Example
In this setup, the fact table holds sales data linked to dimension tables with book, time, and store information.
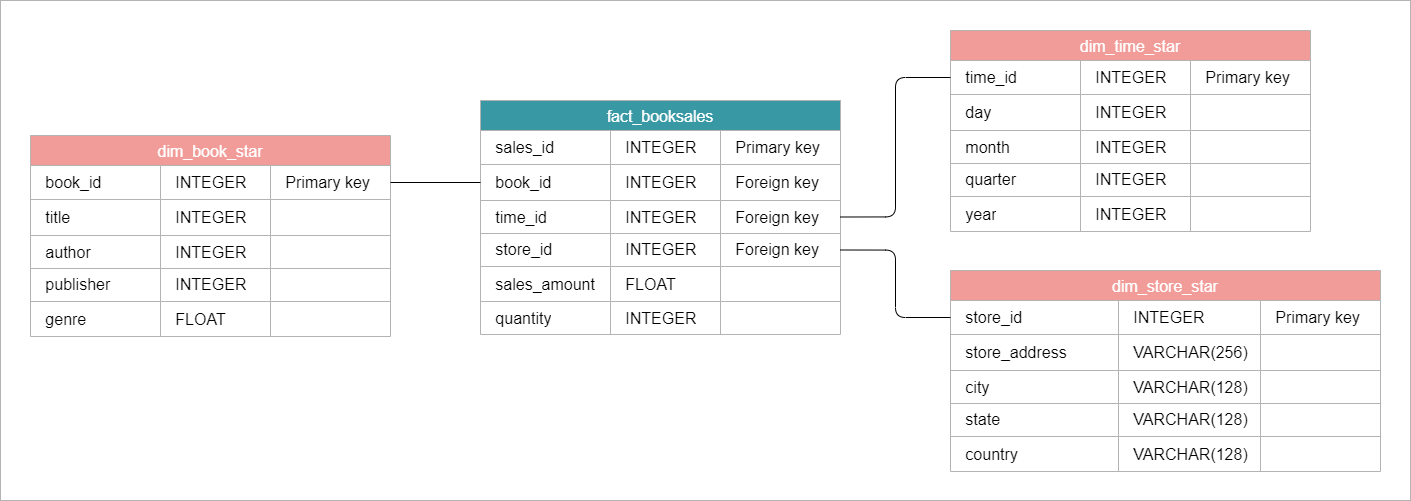
The schema's star shape comes from the one-to-many connections, with stores involved in many sales but each sale tied to a single store.
- Fact table contains key sales metrics.
- Dimension tables include book, time, and store information.
- One-to-many relationships create the star shape.
Create the Tables
Creating the dimension table for books:
CREATE TABLE dim_book_star (
book_id INT PRIMARY KEY,
title VARCHAR(256),
author VARCHAR(256),
publisher VARCHAR(256),
genre VARCHAR(128)
);
SELECT * FROM dim_book_star;

Creating the dimension table for stores:
CREATE TABLE dim_store_star (
store_id INT PRIMARY KEY,
store_address VARCHAR(256),
city VARCHAR(128),
state VARCHAR(128),
country VARCHAR(128)
);
SELECT * FROM dim_store_star;

Creating the dimension table for time:
CREATE TABLE dim_time_star (
time_id INT PRIMARY KEY,
day INT,
month INT,
quarter INT,
year INT
);
SELECT * FROM dim_time_star;

Creating the fact table for book sales:
CREATE TABLE fact_booksales (
sales_id INT PRIMARY KEY,
book_id INT,
time_id INT,
store_id INT,
sales_amount FLOAT,
quantity INT,
FOREIGN KEY (book_id) REFERENCES dim_book_star(book_id),
FOREIGN KEY (time_id) REFERENCES dim_time_star(time_id),
FOREIGN KEY (store_id) REFERENCES dim_store_star(store_id)
);
SELECT * FROM fact_booksales;

Insert Sample Records
Inserting records into dim_book_star:
INSERT INTO dim_book_star VALUES
(5249, '1984', 'George Orwell', 'Secker & Warburg', 'dystopian'),
(5250, 'To Kill a Mockingbird', 'Harper Lee', 'J. B. Lippincott & Co.', 'drama'),
(5251, 'The Great Gatsby', 'F. Scott Fitzgerald', 'Charles Scribner''s Sons', 'novel'),
(5252, 'Catch-22', 'Joseph Heller', 'Simon & Schuster', 'satire'),
(5253, 'Brave New World', 'Aldous Huxley', 'Chatto & Windus', 'dystopian'),
(5254, 'Moby Dick', 'Herman Melville', 'Harper & Brothers', 'adventure'),
(5255, 'War and Peace', 'Leo Tolstoy', 'The Russian Messenger', 'historical fiction'),
(5256, 'Hamlet', 'William Shakespeare', 'N/A', 'tragedy'),
(5257, 'Pride and Prejudice', 'Jane Austen', 'T. Egerton', 'romance'),
(5258, 'The Catcher in the Rye', 'J.D. Salinger', 'Little, Brown and Company', 'novel');
SELECT * FROM dim_book_star;
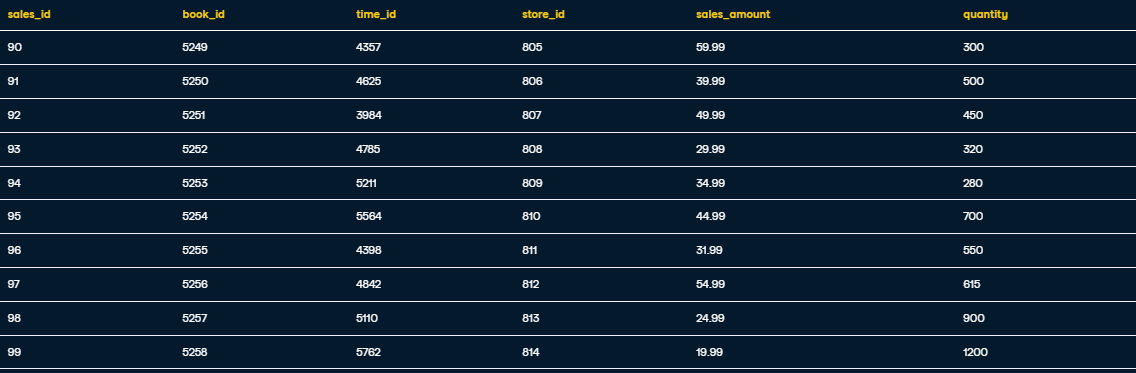
Inserting records into dim_store_star:
INSERT INTO dim_store_star VALUES
(805, '1234 Book St', 'San Francisco', 'California', 'United States of America'),
(806, '5678 Read Ave', 'New York', 'New York', 'USA'),
(807, '91011 Novel Rd', 'Chicago', 'Illinois', 'United States'),
(808, '1213 Story Blvd', 'Los Angeles', 'California', 'US'),
(809, '1415 Chapter Ct', 'Seattle', 'Washington', 'United States of America'),
(810, '1617 Page Ln', 'Boston', 'Massachusetts', 'USA'),
(811, '1819 Ink Dr', 'San Diego', 'California', 'United States'),
(812, '2021 Manuscript Pl', 'Austin', 'Texas', 'US'),
(813, '2223 Script St', 'Denver', 'Colorado', 'United States of America'),
(814, '2425 Prose Pkwy', 'San Jose', 'California', 'USA');
SELECT * FROM dim_store_star;
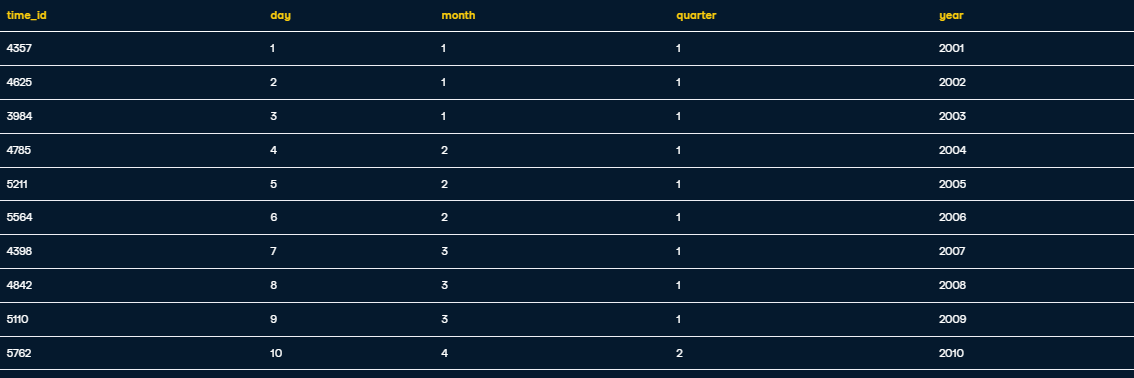
Inserting records into dim_time_star:
INSERT INTO dim_time_star VALUES
(4357, 1, 1, 1, 2001),
(4625, 2, 1, 1, 2002),
(3984, 3, 1, 1, 2003),
(4785, 4, 2, 1, 2004),
(5211, 5, 2, 1, 2005),
(5564, 6, 2, 1, 2006),
(4398, 7, 3, 1, 2007),
(4842, 8, 3, 1, 2008),
(5110, 9, 3, 1, 2009),
(5762, 10, 4, 2, 2010);
SELECT * FROM dim_time_star;
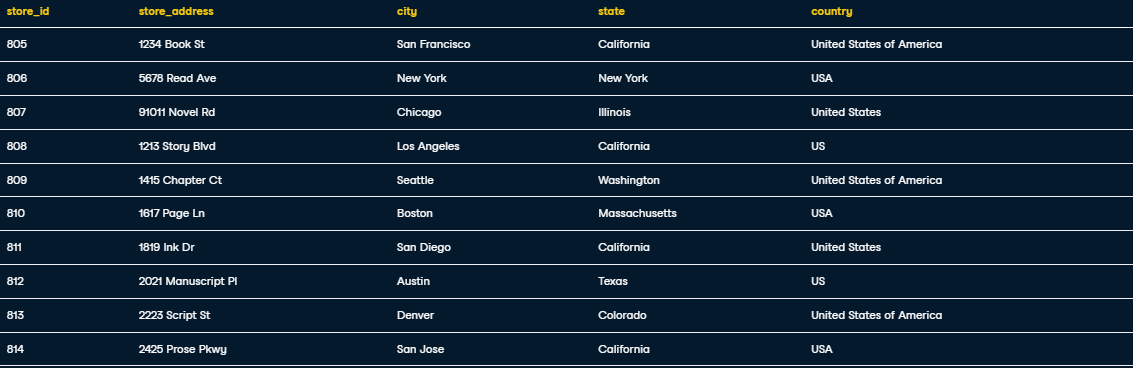
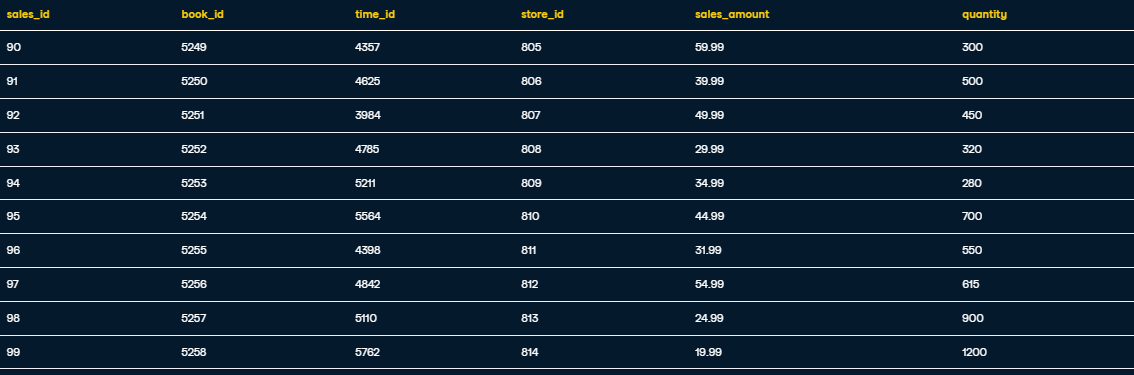
Inserting records into fact_booksales:
INSERT INTO fact_booksales VALUES
(90, 5249, 4357, 805, 59.99, 300),
(91, 5250, 4625, 806, 39.99, 500),
(92, 5251, 3984, 807, 49.99, 450),
(93, 5252, 4785, 808, 29.99, 320),
(94, 5253, 5211, 809, 34.99, 280),
(95, 5254, 5564, 810, 44.99, 700),
(96, 5255, 4398, 811, 31.99, 550),
(97, 5256, 4842, 812, 54.99, 615),
(98, 5257, 5110, 813, 24.99, 900),
(99, 5258, 5762, 814, 19.99, 1200);
SELECT * FROM fact_booksales;
Querying the Star Schema
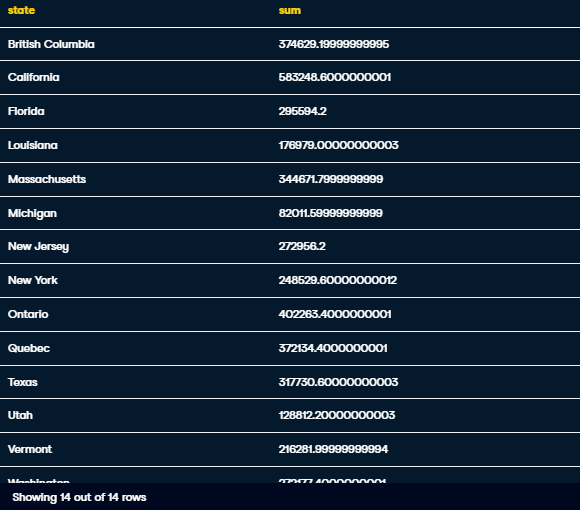
Here we'll look at the total amount of sales made in each state from books in the novel genre.
SELECT dim_store_star.state, SUM(sales_amount)
FROM fact_booksales
JOIN dim_book_star ON dim_book_star.book_id = fact_booksales.book_id
JOIN dim_store_star ON dim_store_star.store_id = fact_booksales.store_id
WHERE
dim_book_star.genre = 'novel'
GROUP BY
dim_store_star.state;

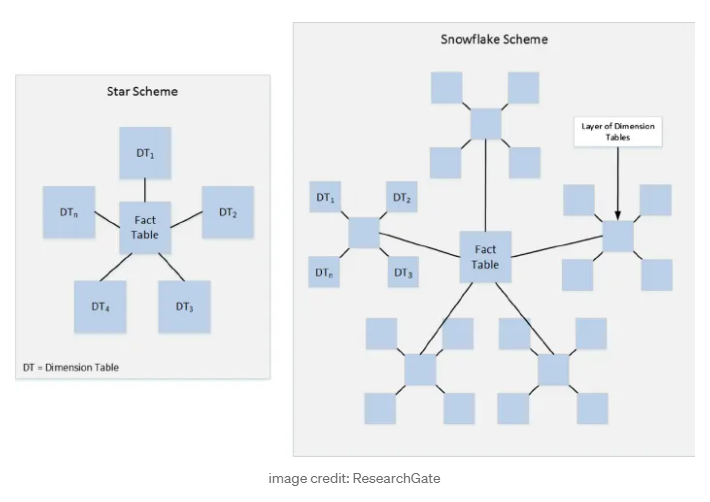
Snowflake Schema
The snowflake schema builds on the star schema by adding more tables and normalizing dimension tables. It gets its name because its structure resembles a snowflake.
- Schema has more tables than the star schema.
- Dimension tables are normalized for more detail.
The star schema extends one dimension, while the snowflake schema extends over more than one dimension. This is because the dimension tables are normalized.
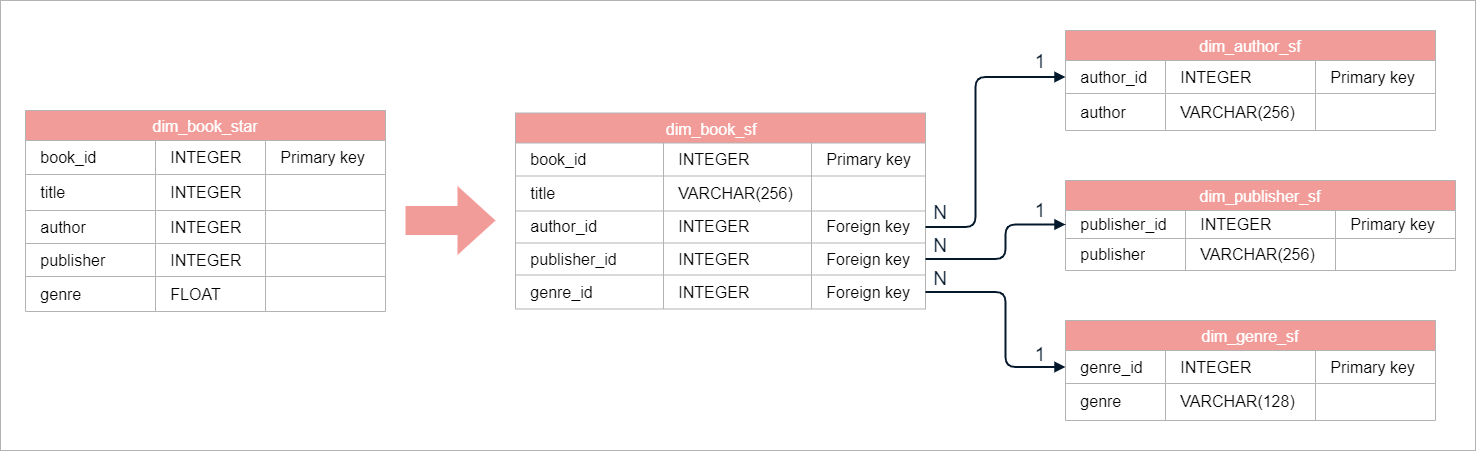
Normalization
Normalization breaks tables into smaller, connected ones to reduce redundancy and boost data integrity. This involves identifying repeating data and creating new tables.
- Identifies repeating data groups and create new tables.
- Organizes data effectively with new tables.
In the star schema's book dimension, elements like authors, publishers, and genres repeat. We can create separate tables for these elements, forming a snowflake schema.
Cities, states, and countries can have multiple bookstores. This dimension extends over three levels: city, state, and country.
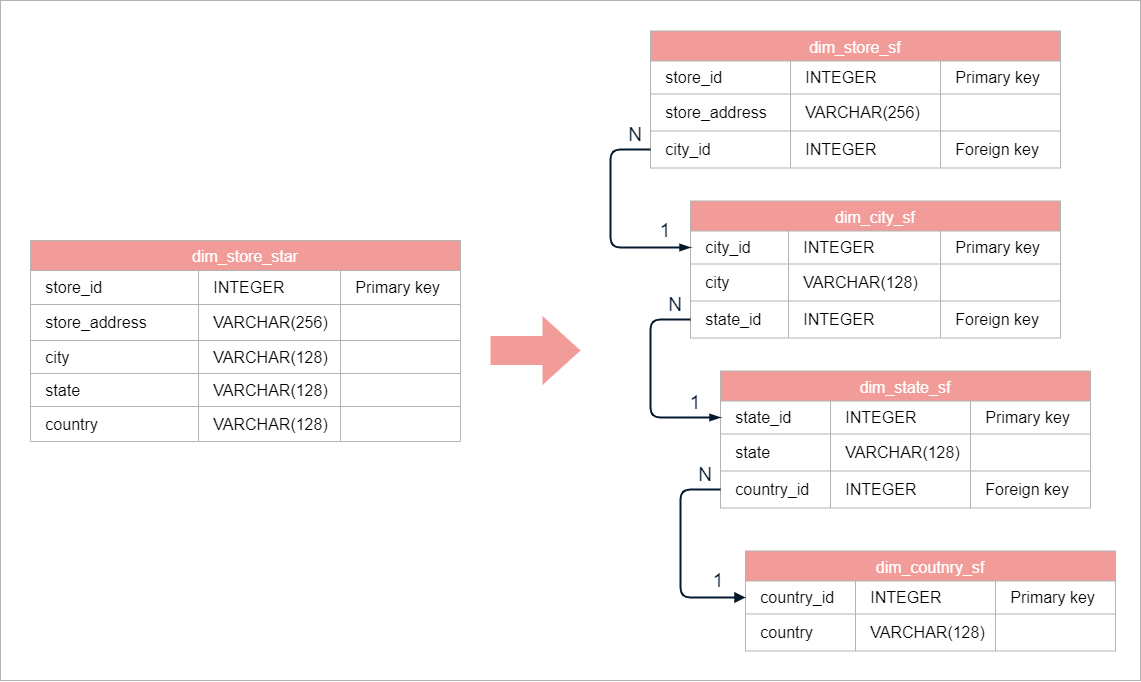
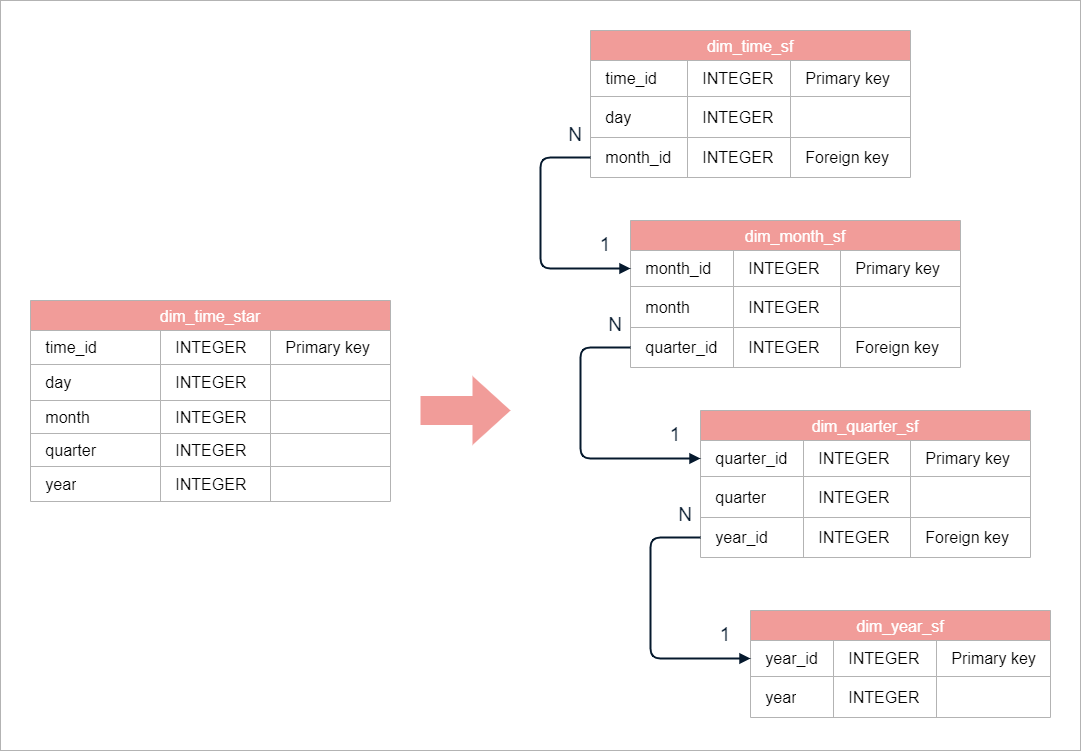
The time dimension has a hierarchy where days are part of months, which are part of quarters, and so on.
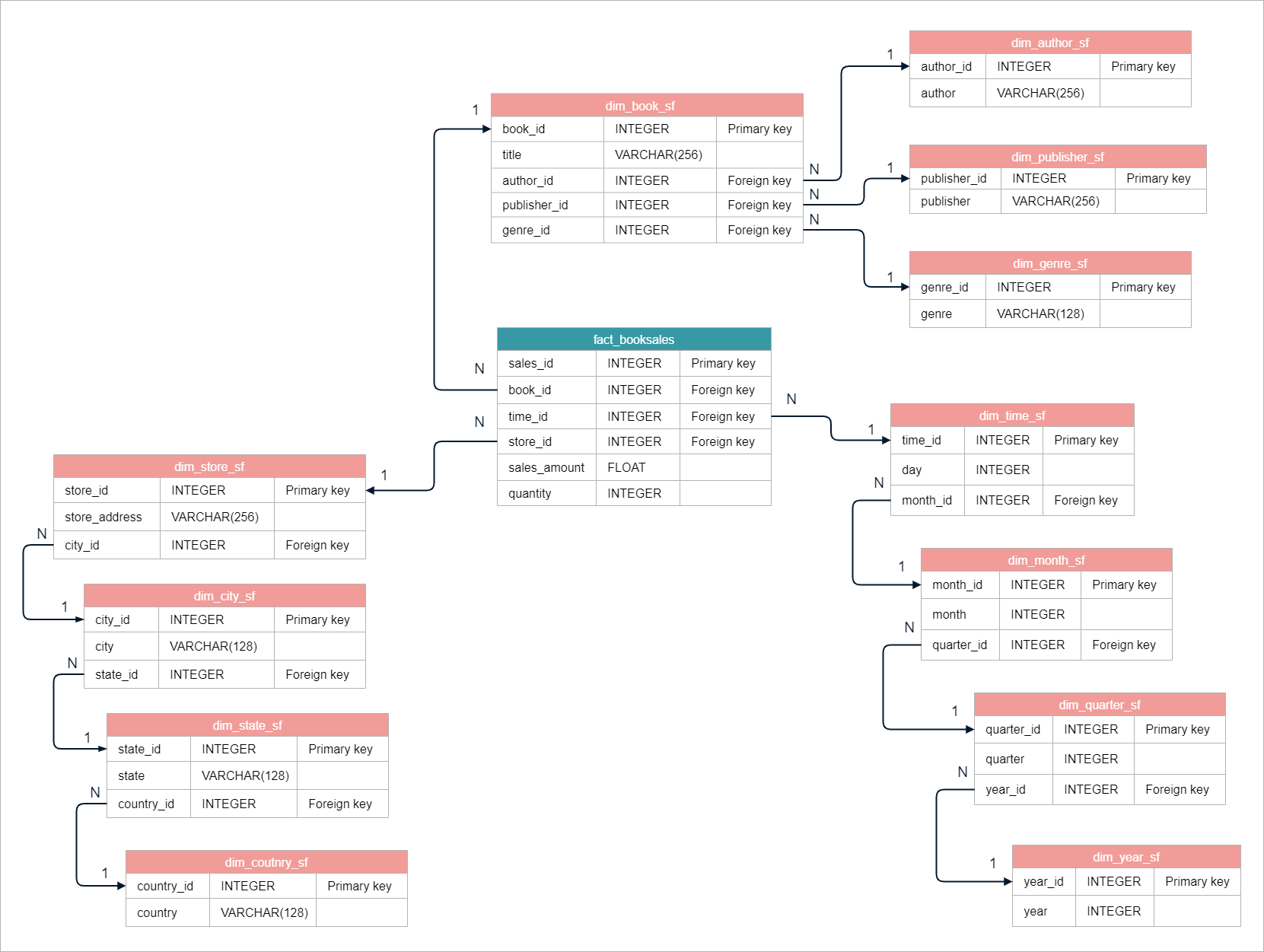
Combining all normalized dimensions together:
Eliminating Redundancy
Normalization reduces data redundancy, which might seem counterintuitive given the increase in the number of tables.
- Normalized databases use more tables but eliminate data redundancy.
- In denormalized structures, repeated entries cause redundancy.
- Normalization reduces repeated entries by using separate tables.
In the denormalized table below, repeated entries like "USA," "California," and "Brooklyn" are common, leading to data redundancy.
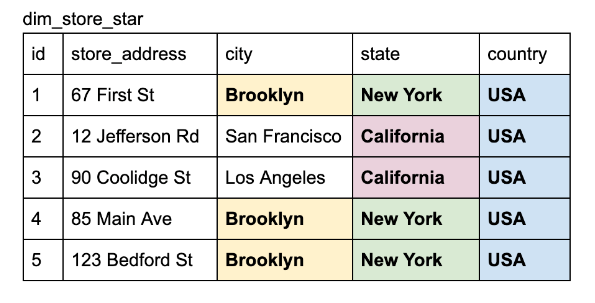
In a normalized schema, redundancy is eliminated. For example, "Brooklyn" is stored only once. States like "California" are also stored separately, as many cities share the same state and country.
Enhancing Data Integrity
Normalization improves data integrity by enforcing consistency and simplifying data modifications. It reduces duplicates, making updates easier and safer.
- Ensures data consistency and simplifies modifications.
- Reduces duplicates, making updates easier and safer.
- Smaller tables make schema alterations easier.
Pros and Cons
Normalization offers benefits like easier maintenance and reduced redundancy. However, it requires more joins, complicating queries and potentially slowing indexing and data reading.
- Provides easier maintenance and reduces redundancy.
- Requires more joins, complicating queries.
- Decision depends on database read or write intensity.
OLTP vs. OLAP Preferences
OLTP and OLAP have different preferences regarding normalization. OLTP is write-intensive while OLAP focuses on read-intensive analytics.
- OLTP benefits from normalization for quick, consistent data addition.
- OLAP avoids normalization to prioritize fast read queries.
- Preferences depend on read or write focus.
Querying Snowflake Schema
Using the previous example, we want to see the total sales for novel genres for each state. The schema looks like this:
To start with, define the basic skeleton of the SQL query:
SELECT
FROM
WHERE
The filter we want is for novel genres, so we'll define this in the WHERE command:
SELECT
FROM
WHERE dim_genre_sf.genre = 'novel'
The expected columns are: state and sum, where sum is the total sales. We know that the sales records can only be found in the fact_booksales table, so we know that it'll be our "base" table. The base table is also called the facts table.
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
WHERE dim_genre_sf.genre = 'novel'
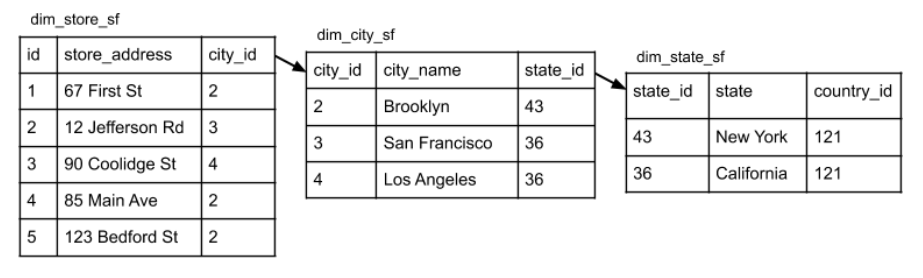
This is not yet finish because we have to get the genre and state. Let's begin with the state. From the "base" table, we can trace the foreign keys-to-primary keys until we reach the table that contains the state attribute.
Note that we can also do the other way around - start from the dimension table that contains the state attribute and trace the tables until we reach the facts table.
- The dim_state_sf table contains the
stateattribute. - Use
state_idto "hop" from dim_state_sf to dim_city_sf table. - Use
city_idto "hop" from dim_city_sf to dim_store_sf table. - Use
store_idto "hop" from dim_store_sf to fact_booksales table.
To translate this to SQL commands, we can use `JOIN':
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
-- Get state
JOIN dim_state_sf ON dim_city_sf.state_id = dim_state_sf.state_id
JOIN dim_city_sf ON dim_store_sf.city_id = dim_city_sf.city_id
JOIN dim_store_sf ON fact_booksales.store_id = dim_store_sf.store_id
WHERE dim_genre_sf.genre = 'novel'
However, if we run this query, we'll get an error:
missing FROM-clause entry for table "dim_city_sf"
LINE 4: JOIN dim_state_sf ON dim_city_sf.state_id = dim_state_sf...
^
The reason for this error is because we did the "reverse route" where we started from the dimension table and traced all the way to the facts table. However, SQL starts at the facts table which is defined by the WHERE statement and works its way to the dimension table.
So we just need to rearrange the command:
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
-- Get state
JOIN dim_store_sf ON fact_booksales.store_id = dim_store_sf.store_id
JOIN dim_city_sf ON dim_store_sf.city_id = dim_city_sf.city_id
JOIN dim_state_sf ON dim_city_sf.state_id = dim_state_sf.state_id
WHERE dim_genre_sf.genre = 'novel'
If we try to run this again, we'll get another error:
column "dim_genre_sf" does not exist
LINE 7: WHERE dim_genre_sf.genre = 'novel'
^
The reason of this error is because we haven't retrieve the genre yet. We can use JOIN here as well.
- The dim_genre_sf table contains the
genreattribute. - From fact_booksales table, we need to reach the dim_genre_sf table.
- Use
book_idto "hop" from fact_booksales table to dim_book_sf table. - Use
genre_idto "hop" from dim_book_sf table to dim_genre_sf table
Translating to SQL query:
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
-- Get state
JOIN dim_store_sf ON fact_booksales.store_id = dim_store_sf.store_id
JOIN dim_city_sf ON dim_store_sf.city_id = dim_city_sf.city_id
JOIN dim_state_sf ON dim_city_sf.state_id = dim_state_sf.state_id
-- Get genre
JOIN dim_book_sf ON dim_book_sf.book_id = fact_booksales.book_id
JOIN dim_genre_sf ON dim_genre_sf.genre_id = dim_book_sf.genre_id
WHERE dim_genre_sf.genre = 'novel'
We can change the order when comparing similar attributes between two different tables. This means that this arrangement:
JOIN dim_book_sf ON dim_book_sf.book_id = fact_booksales.book_id
JOIN dim_genre_sf ON dim_genre_sf.genre_id = dim_book_sf.genre_id
is the same as:
JOIN dim_book_sf ON fact_booksales.book_id = dim_book_sf.book_id
JOIN dim_genre_sf ON dim_book_sf.genre_id = dim_genre_sf.genre_id
To remove confusion, we'll just follow the same order for all JOIN:
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
-- Get state
JOIN dim_store_sf on dim_store_sf.store_id = fact_booksales.store_id
JOIN dim_city_sf on dim_city_sf.city_id = dim_store_sf.city_id
JOIN dim_state_sf on dim_state_sf.state_id = dim_city_sf.state_id
-- Get genre
JOIN dim_book_sf ON dim_book_sf.book_id = fact_booksales.book_id
JOIN dim_genre_sf ON dim_genre_sf.genre_id = dim_book_sf.genre_id
WHERE dim_genre_sf.genre = 'novel'
If we try to run this, we'll get another error:
column "dim_state_sf.state" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: SELECT dim_state_sf.state, SUM(sales_amount)
^
This error is related to the SUM function in the SELECT statement. When we use aggregate functions like SUM() and also select other columns, those columns must either be included in a GROUP BY clause or used within an aggregate function themselves. This ensures that the query knows how to group the non-aggregated data.
Basically, the SUM(sales_amount) is aggregated but dim_state_sf.state is not. So we need to group the results by dim_state_sf.state:
SELECT dim_state_sf.state, SUM(sales_amount)
FROM fact_booksales
-- Get state
JOIN dim_store_sf on dim_store_sf.store_id = fact_booksales.store_id
JOIN dim_city_sf on dim_city_sf.city_id = dim_store_sf.city_id
JOIN dim_state_sf on dim_state_sf.state_id = dim_city_sf.state_id
-- Get genre
JOIN dim_book_sf ON dim_book_sf.book_id = fact_booksales.book_id
JOIN dim_genre_sf ON dim_genre_sf.genre_id = dim_book_sf.genre_id
WHERE dim_genre_sf.genre = 'novel'
GROUP BY dim_state_sf.state;
Finally, it returns an output: