OLAP and OLTP
How should we manage data?
- Schemas: How should my data be logically organized?
- Normalization: Should my data have minimal dependency and redundancy?
- Views: What joins will be done most often?
- Access Control: Should all users of the data have the same level of access?
- DBMS: How do I pick between all the SQL and NoSQL options?
Approaches to Data Processing
Two main approaches, OLTP and OLAP, serve different purposes in processing data.
-
OLTP
- Designed for handling routine transactions quickly.
- Used for tasks like tracking book prices and processing sales.
- Supports daily operations with frequent, simple tasks.
- Accessible to a wide range of users for smooth operations.
-
OLAP
- Focuses on long-term data analysis for decision-making.
- Used for identifying sales trends and top-selling books.
- Handles complex queries for comprehensive insights.
- Accessed mainly by analysts and data scientists.
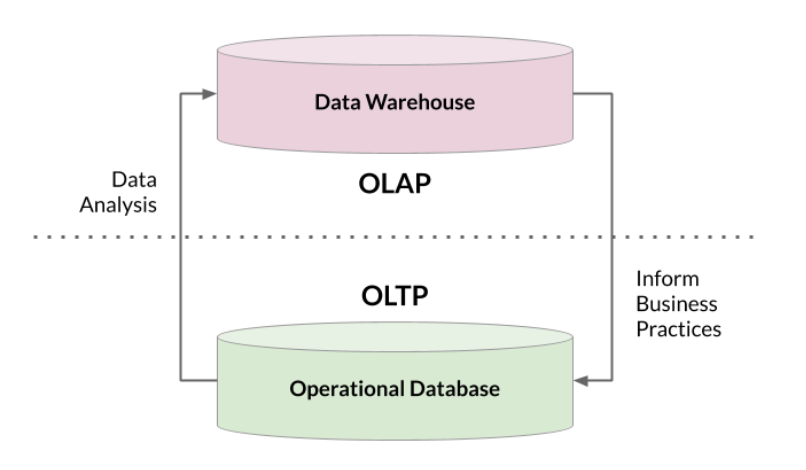
Working Together
OLTP and OLAP systems complement each other to enhance data management.
- OLTP data is extracted for OLAP analysis in data warehouses.
- OLAP insights refine business practices and influence OLTP transactions.
- Their synergy turns transactional data into strategic insights.
Choosing the right data processing approach is essential for a functional database system.
Traditional Databases
Traditional databases are typically relational and used for operational tasks (OLTP). While they were sufficient for storage in the past, the growth of data analytics and big data required more advanced storage solutions like data warehouses and data lakes.
- Traditional databases follow relational schemas for OLTP.
- Shift from databases to warehouses and lakes for enhanced analytics and storage.
Data Warehouses
Data warehouses are designed for read-only analytics, integrating data from various sources to support fast queries using massively parallel processing.
- Optimized for analytics with fast queries.
- Utilize dimensional modeling and denormalized schemas.
- Examples: Amazon Redshift, Google BigQuery, Microsoft Azure SQL Data Warehouse.
- Data marts: Specialized subsets for specific data needs.
Data Lakes
Data lakes provide cost-effective object storage for massive amounts of structured and unstructured data.
- Retains all data and can take up petabytes.
- Store vast amounts of diverse data types.
- Support schema-on-read - creating schemas as data is accessed
- Need to catalog data well, or it becomes a data swamp
- Popular for analytics in deep learning and discovery.
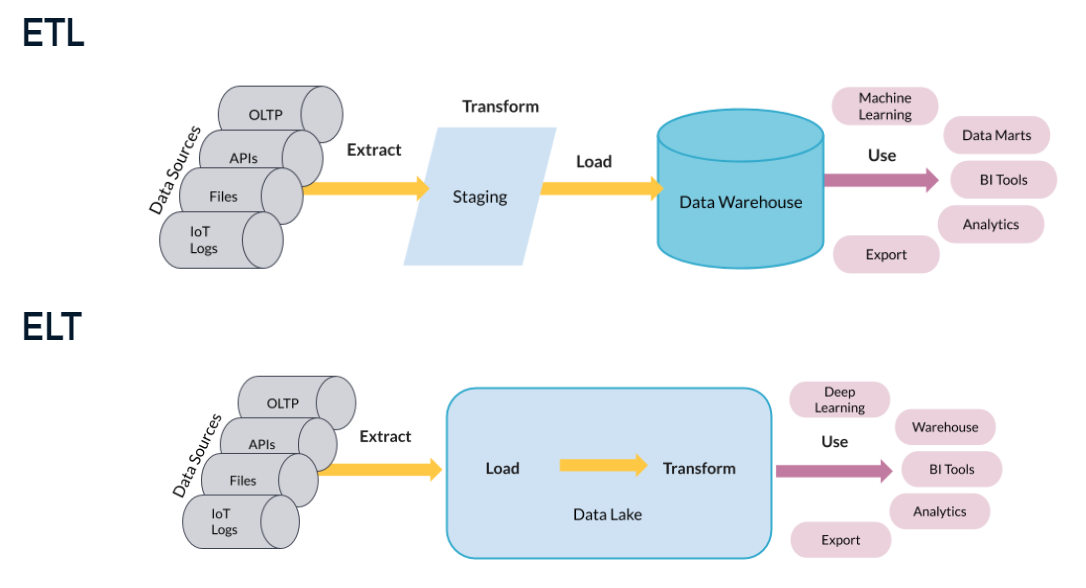
Extract, Transform, Load
ETL and ELT are methods for managing data flows and pipelines. ETL is the traditional approach, transforming data before storage to fit predefined schemas. ELT stores data in its native form and transforms it as needed, making it suitable for big data projects and flexible analysis.
- ETL: Transforms data before storage, suited for traditional warehousing.
- ELT: Stores raw data, transforming later for specific needs, ideal for big data.
- ETL vs. ELT: Choice depends on storage strategy and data processing needs.
Diagram: