Table Partitioning
Why Partition?
Table partitioning helps manage large datasets efficiently. As tables grow into hundreds of gigabytes or terabytes, query performance can degrade, even with well-set indices.
- Large indices may not fit into memory, slowing queries.
- Partitioning involves splitting a table into smaller, manageable parts.
Partitioning is part of the physical data model but doesn't alter the logical structure of data. This means that data remains logically unchanged but is distributed across multiple physical entities.
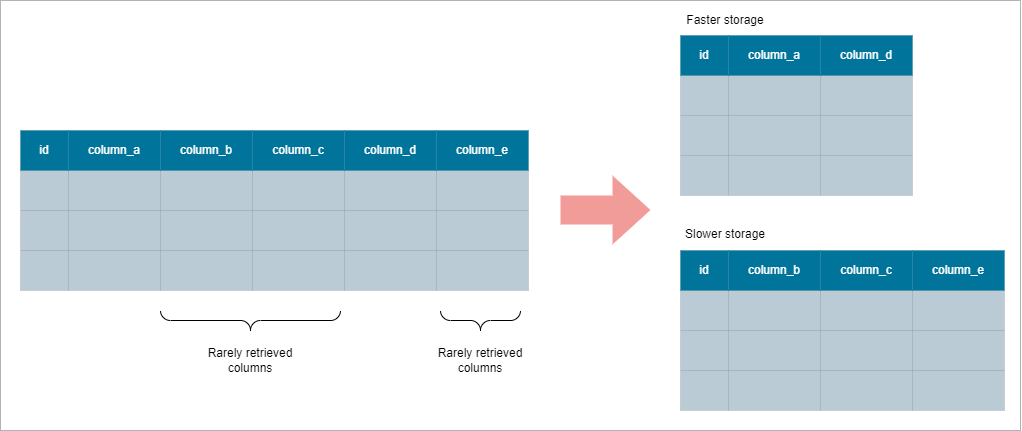
Vertical Partitioning
Vertical partitioning splits a table into smaller tables based on columns, even if the table is already normalized.
- This approach reduces redundant data by using foreign keys to link tables.
- It further divides a table by columns for better efficiency.
Consider a table with five columns. We can use vertical partitioning to divide it into two tables and link both tables with a shared key called id. Rarely access columns can be placed slower media to improve query times for frequently accessed data, as we need to scan less data for search queries.
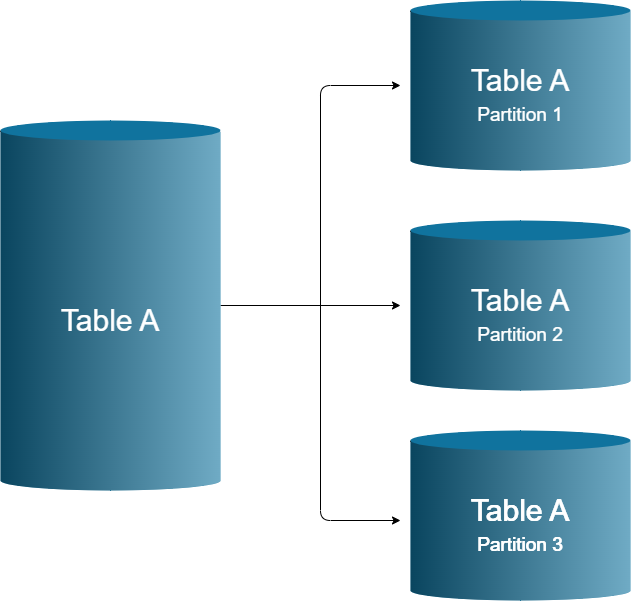
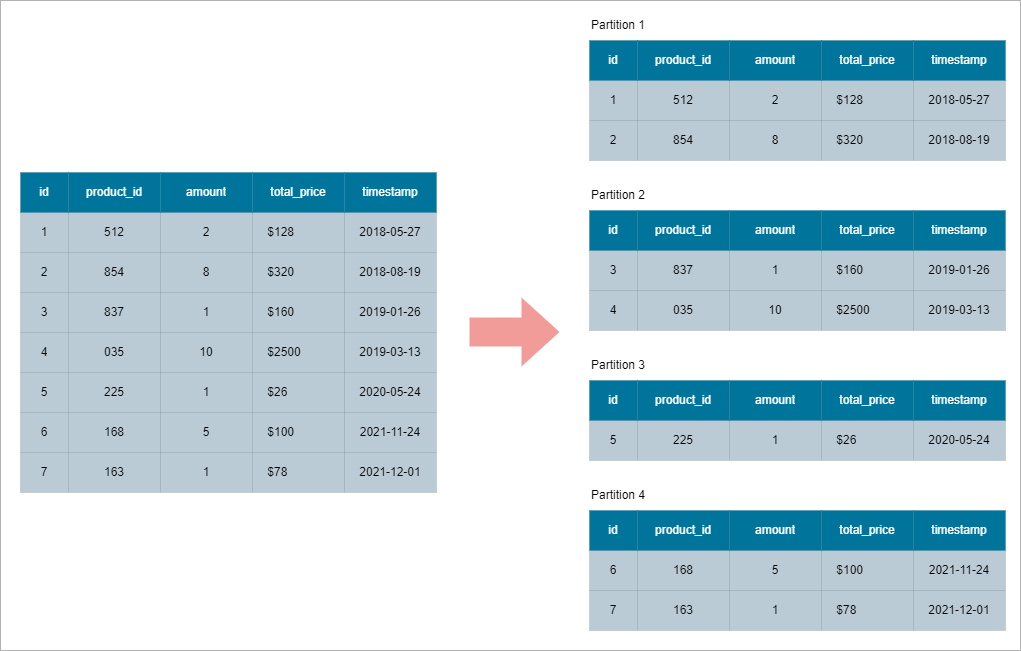
Horizontal Partitioning
Horizontal partitioning splits a table into smaller tables based on rows instead of columns.Partition Data can be partitioned by criteria, like for example, using timestamps to separate data from different years into distinct partitions.
PostgreSQL has a declarative partitioning feature where we can use PARTITION BY when creating the tables.
- Create specific partitions using
PARTITION OF, specifying ranges. - Add an index to the partitioning column for optimized performance.
Syntax:
-- Specify the partition criteria when creating the database
CREATE TABLE product_sales (
...
timestamp DATE NOT NULL
)
PARTITION BY RANGE (timestamp);
-- Create the partitions
CREATE TABLE product_sales__2018
PARTITION OF product_sales
FOR VALUES FROM ('2018-01-01') TO ('2018-12-31');
CREATE TABLE product_sales__2019
PARTITION OF product_sales
FOR VALUES FROM ('2019-01-01') TO ('2019-12-31');
CREATE TABLE product_sales__2020
PARTITION OF product_sales
FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE product_sales__2021
PARTITION OF product_sales
FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
-- Create the index
CREATE INDEX ON product_sales ('timestamp');
Pros and Cons: Horizontal Partitioning
Pros:
- Indices fit better in memory, boosting performance.
- Rarely used partitions can be stored on slower media.
- Enhances performance for both OLAP and OLTP systems.
- Queries can target specific partitions, speeding up access.
Cons:
- Requires creating new tables and copying data, which is complex.
- Some constraints, like PRIMARY KEY, may not apply uniformly.
- Increases complexity in database administration.
- Partitions may become unevenly distributed over time.
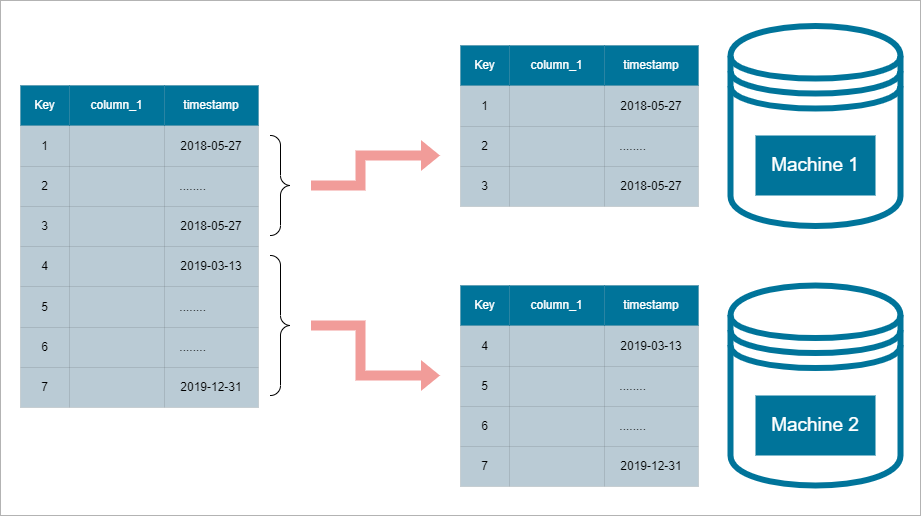
Sharding
Sharding involves using horizontal partitioning to distribute a table across multiple machines. This approach is useful in massively parallel processing databases, allowing each machine, or node, to handle computations on its own data shard.
Example
Sample Table
We'll be using the film dataset.
To download the actual file, you can get it from my Github repository:
Creating Vertical Partitions
To-dos:
- Drop the field long_description from the film table.
- Join the two resulting tables to view the original table.
Solution
Run the query below:
-- Create a new table called film_descriptions
CREATE TABLE film_descriptions (
film_id INT,
long_description TEXT
);
-- Copy the descriptions from the film table
INSERT INTO film_descriptions
SELECT film_id, long_description FROM film;
-- Drop the descriptions from the original table
ALTER TABLE film
DROP COLUMN long_description;
-- Join to view the original table
SELECT * FROM film
JOIN film_descriptions USING(film_id);
Creating Horizontal Partitions
To-dos:
- Create the table
film_partitioned, partitioned on the fieldrelease_year. - Create three partitions: one for each release year: 2017, 2018, and 2019.
- Call the partition for 2019
film_2019, etc. - Occupy the new table, film_partitioned, with the three fields required from the film table.
Solution
Create a new table called film_partitioned:
CREATE TABLE film_partitioned (
film_id INT,
title TEXT NOT NULL,
release_year TEXT
)
PARTITION BY LIST (release_year);
SELECT * FROM film_partitioned;

Create the partitions for 2019, 2018, and 2017:
CREATE TABLE film_2019
PARTITION OF film_partitioned FOR VALUES IN ('2019');
CREATE TABLE film_2018
PARTITION OF film_partitioned FOR VALUES IN ('2018');
CREATE TABLE film_2017
PARTITION OF film_partitioned FOR VALUES IN ('2017');
Insert the data into film_partitioned:
INSERT INTO film_partitioned
SELECT
film_id,
title,
release_year
FROM film;
-- View film_partitioned
SELECT * FROM film_partitioned;
