Deployment Strategies
Overview
Deploying a new machine learning model requires careful planning, especially in real-time systems. Below are different deployment strategies, their use cases, and examples.
Basic Deployment
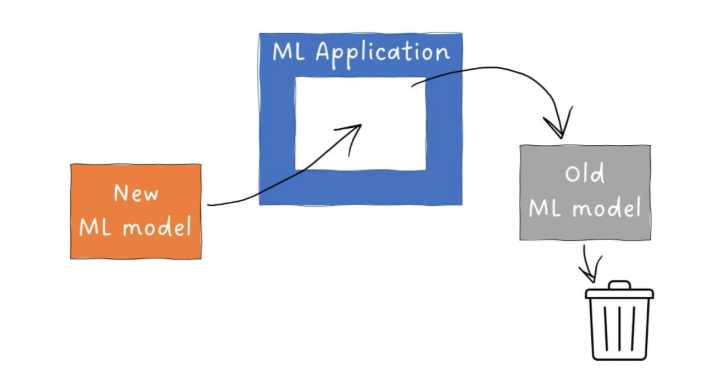
In basic deployment, the new model fully replaces the old one in production. If the model runs in batch mode, a direct swap is the easiest approach.
- Works well for scheduled batch predictions
- Minimal risk if deployed between runs
- If the new model fails, all users are affected.
Example: A daily sales forecast model can be updated between runs without affecting users.
Blue/Green Deployment
For real-time prediction services, even brief downtime can be disruptive.
- Models handling thousands of requests per minute cannot be paused
- Any interruption can impact users and business operations
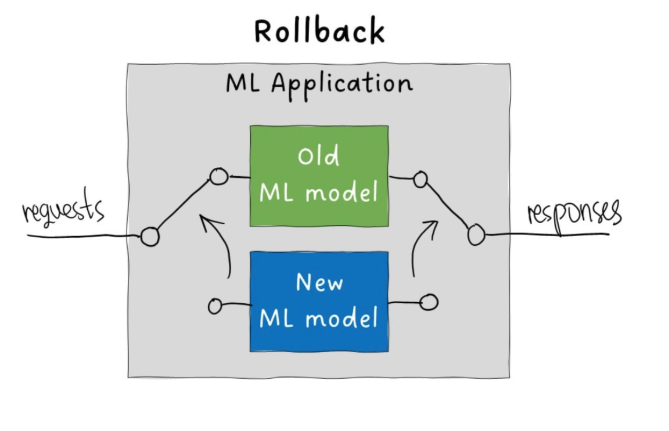
To prevent downtime, the Blue/Green Deployment strategy enables model switching without service disruption.
- Load new model in the background while serving the old one
- Once ready, redirect traffic to the new model
- Keep the old model available for rollback
Pros:
- No downtime
- Instant model switch
Cons:
- If the new model fails, all users are affected
If needed, we can quickly roll back to the old model and continue using it until the issue with the new model is resolved.
Canary Deployment
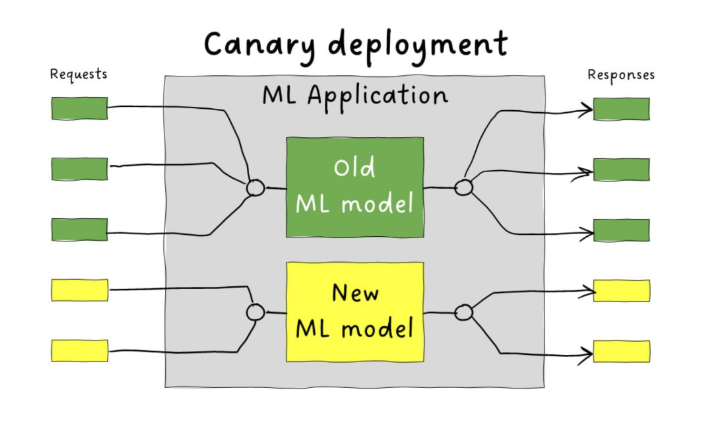
This method gradually shifts traffic to the new model to minimize risk.
- Start with a small percentage (e.g., 5-10%) of requests to the new model
- Monitor performance and compare outputs
- Increase traffic in steps if no issues occur
If the new model performs well, we gradually increase the traffic to it. We repeat this until we're confident it can handle all client requests.
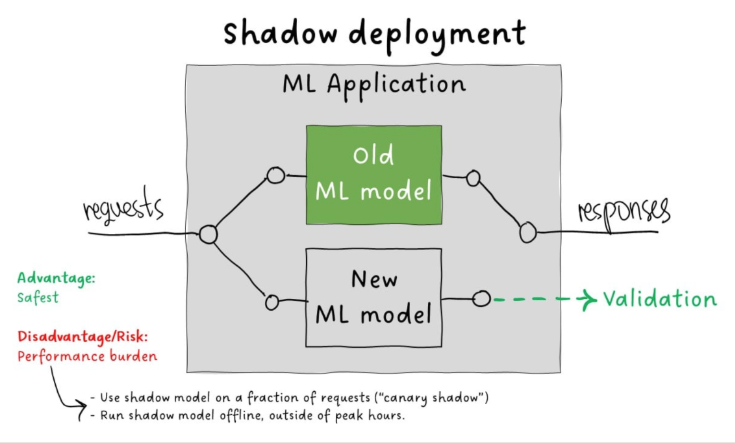
Shadow Deployment
This approach runs the new model in parallel without affecting users.
- Requests are sent to both models, but only the old model's responses are used
- The new model’s outputs are logged for validation
Pros:
- Safest validation method
- No user impact
Cons:
- Requires extra computation
- Can slow down performance in real-time systems
To optimize, limit shadow requests to a sample or schedule batch processing during low-traffic periods.