Monitoring
Overview
To guarantee the quality of our ML models, we need to monitor both system health and prediction accuracy. This are some key health indicators that we need to monitor:
- Service uptime
- Request volume and success rate
- Latency levels
These indicators help maintain overall system stability. However, ensuring the quality of predictions is even more crucial.
Concept Drift
Concept drift occurs when the relationship between input and output features changes over time.
- Leads to incorrect predictions, even though model hasn't changed:
- The model might continue using outdated boundaries for classification.
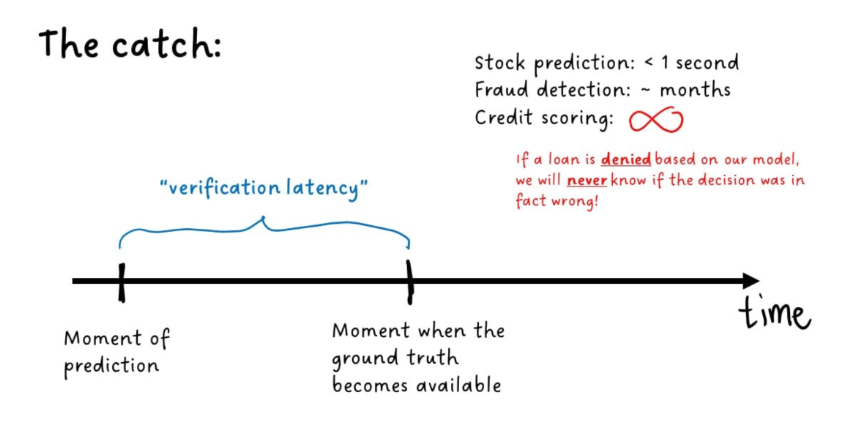
Since ground truth is often delayed, we can't always verify predictions right away. The time between making a prediction and when the true result becomes available, also known as verification latency, makes detecting concept drift more challenging.
Covariate Shift
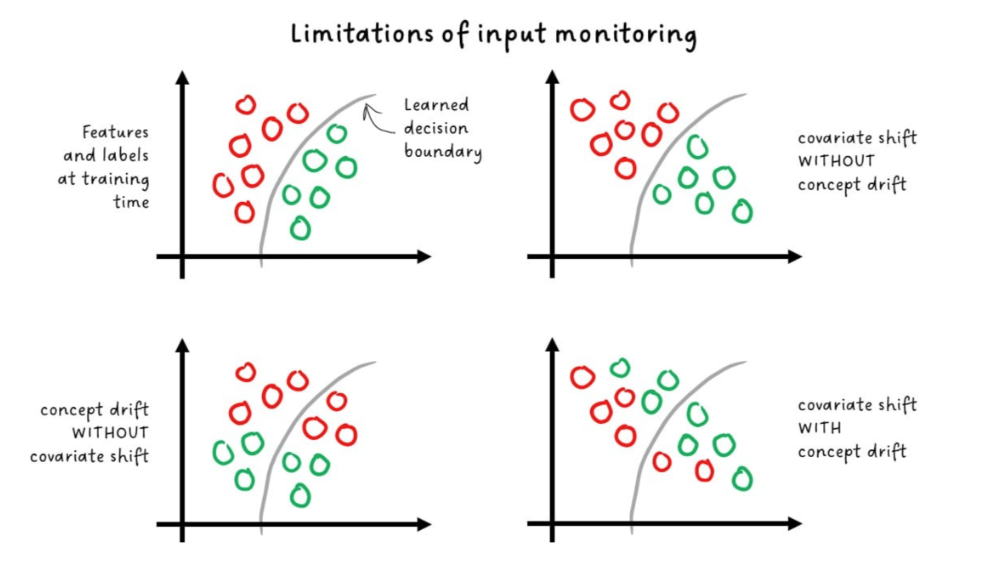
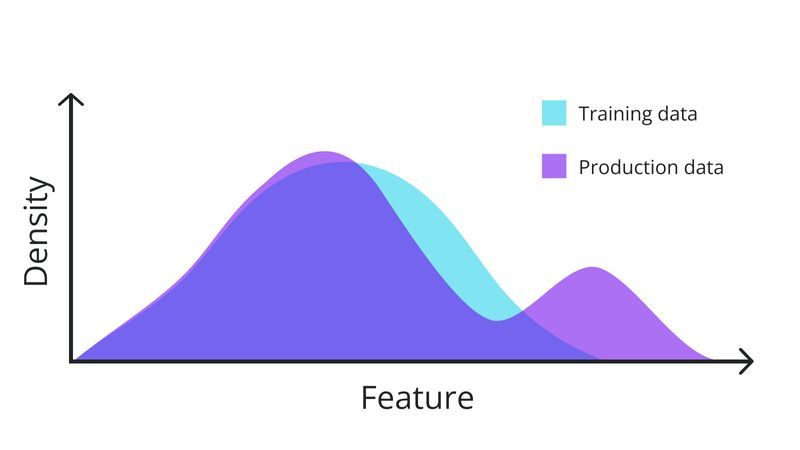
Covariate shift occurs when the input features change over time. It is a good indicator of concept drift but it is not perfect.
- Can happen without any covariate shift
- Can also occur at the same time as concept shift as well
Monitoring these shifts helps us identify when the model may need adjustments, though it doesn't always guarantee concept drift.
Outputs
When ground truth is unavailable, monitoring output changes becomes vital. If the model’s predictions begin to differ from expected patterns, it may indicate the model needs updating.
Monitoring and Alerting
To ensure service quality, we need a monitoring and alerting system to quickly detect and fix issues like bugs, data errors, and failures in our ML service.
Key components of a good monitoring system:
-
Detailed logging
- Capture detailed logs throughout the code.
- Log latency sources and user data.
- Identify the root cause of issues.
-
Data validation
- Validate incoming and outgoing data early.
- Check individual input tables.
- Monitor data quality against predefined rules.
-
Data profiles
- Define acceptable input values and relationships.
- Set ranges and missing data limits.
- Track feature consistency.
-
Statistical validation
- Validate data with clear thresholds.
- Set limits for acceptable variations.
- Avoid excessive alerts for minor changes.
-
Alerting
- Ensure timely and actionable alerts.
- Send alerts to the right team.
- Make alerts clear and easy to act on.
For better efficiency, the monitoring system should be centralized and independent, ensuring high-quality service across all ML services.