Serving Modes
Overview
Model serving is how we provide predictions to users as a service, much like any other service. Users expect to get predictions when they request them, and we need to decide how to deliver them.
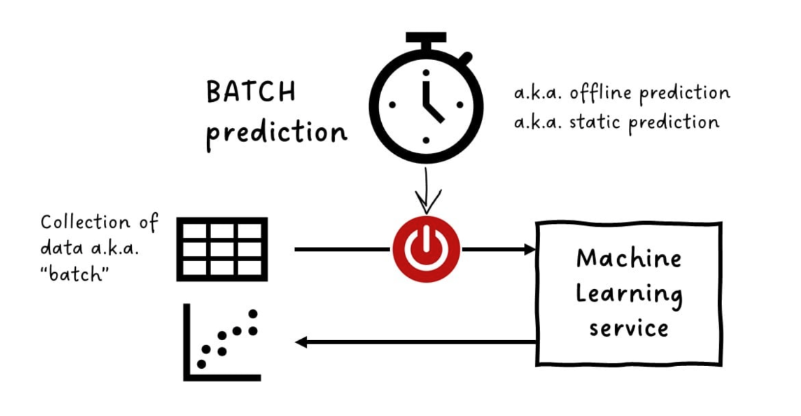
Batch Prediction
Batch prediction involves generating predictions on a set schedule, like once a day or week.
- Predictions run on a large dataset at once
- Best for static or offline predictions like monthly sales forecasts
- Simplest to implement; go for this if use case allows
Batch prediction is suitable for tasks that don't require real-time responses. This makes it easy to manage and scale.
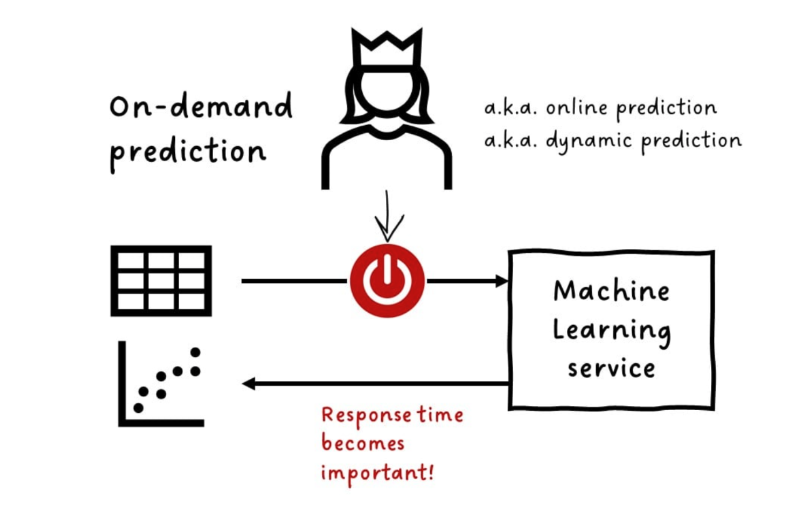
On-demand Prediction
On-demand prediction generates predictions when an event occurs or a user makes a request. This method is more flexible than batch prediction.
- Triggered by events or user requests
- Ideal for use cases that require timely predictions
- More complex to implement than batch prediction
On-demand prediction provides flexibility and responsiveness, and allows users to get predictions when they need them.
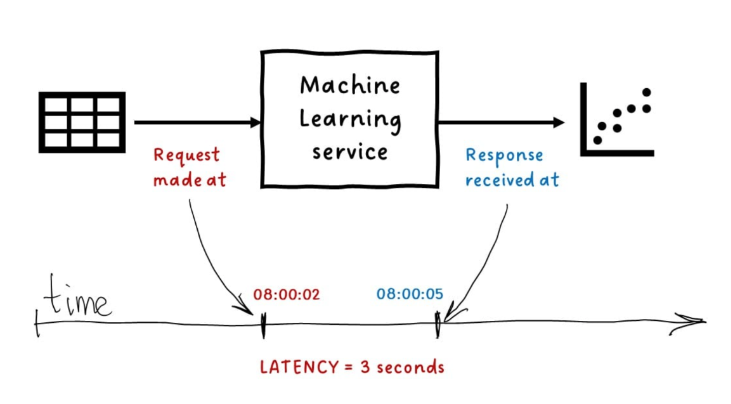
Latency Types
Latency refers to the time it takes for a model to respond after receiving a request. The acceptable latency varies depending on the use case.
-
Near-real-time
- Predictions take minutes, suitable for stream processing
- Requests and responses are called data streams
-
Real-time
- Predictions takes less than a second,
- For high-priority use cases like fraud detection
Lower latency means faster predictions, but it can require stronger infrastructure or model optimization.
Edge Deployment
Edge deployment involves running models directly on users' devices. This minimizes latency by eliminating the need for cloud-based predictions.
- Reduces latency to almost zero
- Models run on smartphones, tablets, or other devices
- Example: facial recognition, image filters, and navigation
Edge deployment improves speed and reduces dependence on cloud resources, and makes it ideal for applications requiring immediate responses.