Profiling and Versioning
Overview
Data profiling automates the analysis of data to create summaries that help us validate and monitor data in production.
- Data profiling – Creates summaries of data to identify issues.
- Data profiles – Validate user inputs and track model performance.
Data Profiles
Data profiles help detect invalid inputs and monitor when retraining is needed. They are used as feedbacks given to the user if they are providing wrong inputs.
When we don't use data profiles, we risk getting errors and performance issues.
-
Erroneous inputs
- Users may provide incorrect data
- Leads to wrong predictions
-
Data drift
- Without monitoring, we may miss when data changes
- Model becomes invalid, which affects performance
ML Pipeline Checklist
This checklist helps ensure that all key aspects of the ML pipeline are covered.
☑ Ensure the code is versioned ☑ Ensure the data is versioned ☑ Train the model ☑ Save the model ☑ Create the data profile ☑ Record exact version of training data
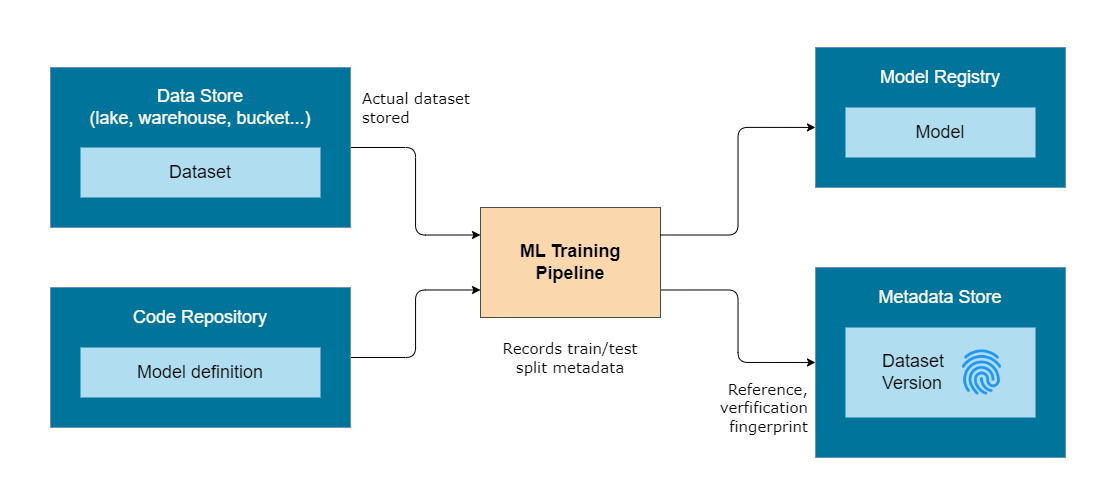
As part of the checklist, we also need to ensure we have the exact version of the training data. This is called data versioning.
Data Versioning
Data versioning tracks the version of data used for training to ensure models are reproducible.
- The full training dataset is not stored in the package.
- The data is stored in a centralized data store.
- A pointer is created to reference the stored data.
- A dataset fingerprint verifies data consistency.
The training pipeline also records metadata to recreate the exact train-test split used for performance evaluation.
For more details on data versioning, please see DVC for Data Versioning.