Clustering Algorithm
Overview
Clustering uses machine learning algorithms to group data into categories, or clusters. This technique reveals patterns in complex datasets, aiding in tasks such as customer segmentation, image categorization, and behavior analysis.
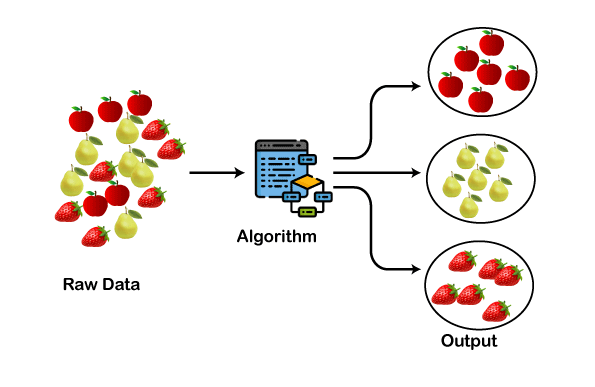
Clustering is also a type of Unsupervised Learning.
- Supervised Learning requires data with labels and features
- Unsupervised Learning only uses features
Unsupervised Learning's features makes clustering especially useful when detailed information about the dataset is not available.

Example: Identifying New Flower Species
Scenario: You are a botanist exploring a new island and you discover several types of flowers you haven’t seen before. You want to determine how many new species you’ve found and how to classify them.
-
Start by defining features. With measurements from over 100 flowers, you can use these as features for the clustering model. This is an unsupervised problem because you have features but lack labels or information on the number of species.
- Flower colors
- Petal length and width
- Sepal length and width
- Number of petals
-
Specify the number of clusters. This decision affects how the algorithm segments your data. By plotting features like petal width, sepal length, and number of petals, you can visualize how different cluster counts affect the results.
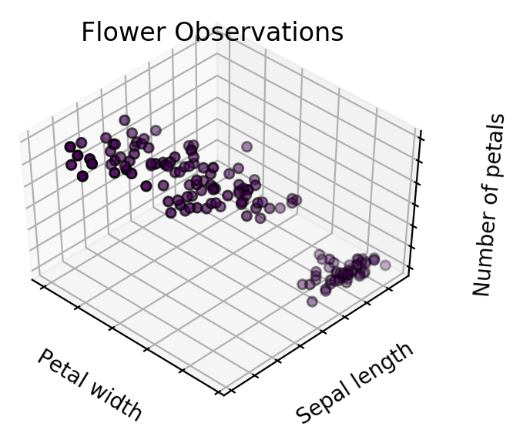
The algorithm’s results may vary with different cluster numbers:
-
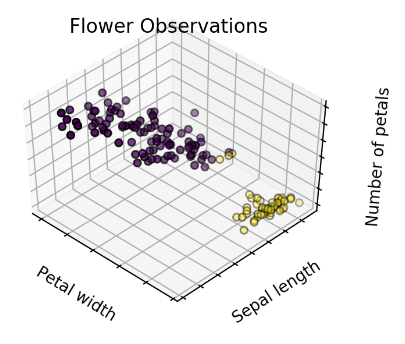
Two clusters: May indicate one new species.
-
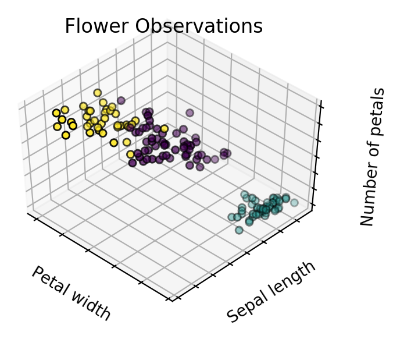
Three clusters: Adds more segmentation.
-
Four and eight clusters: Eight might be excessive, as it may not clearly define distinct groups.
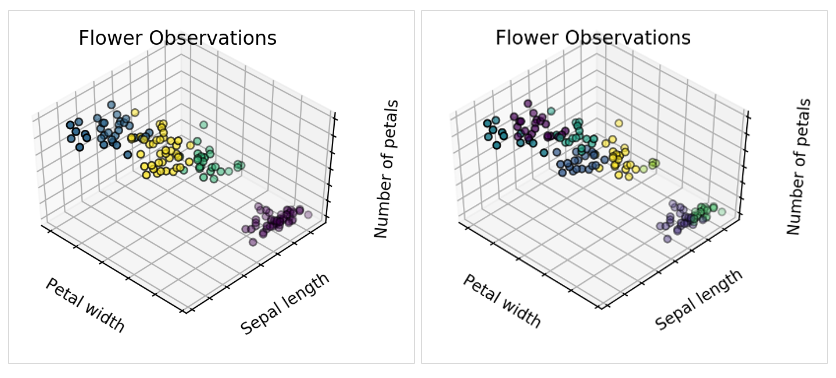
Clustering helps in making informed decisions but doesn’t specify the exact number of clusters. In our case, three or four clusters may be ideal for identifying new species. We can also leverage your botanical knowledge, such as understanding petal width variance, to improve clustering results.