Machine Learning Workflow
Overview
In machine learning, having a clear workflow is key to getting good results. The order in which steps are done plays a big role.
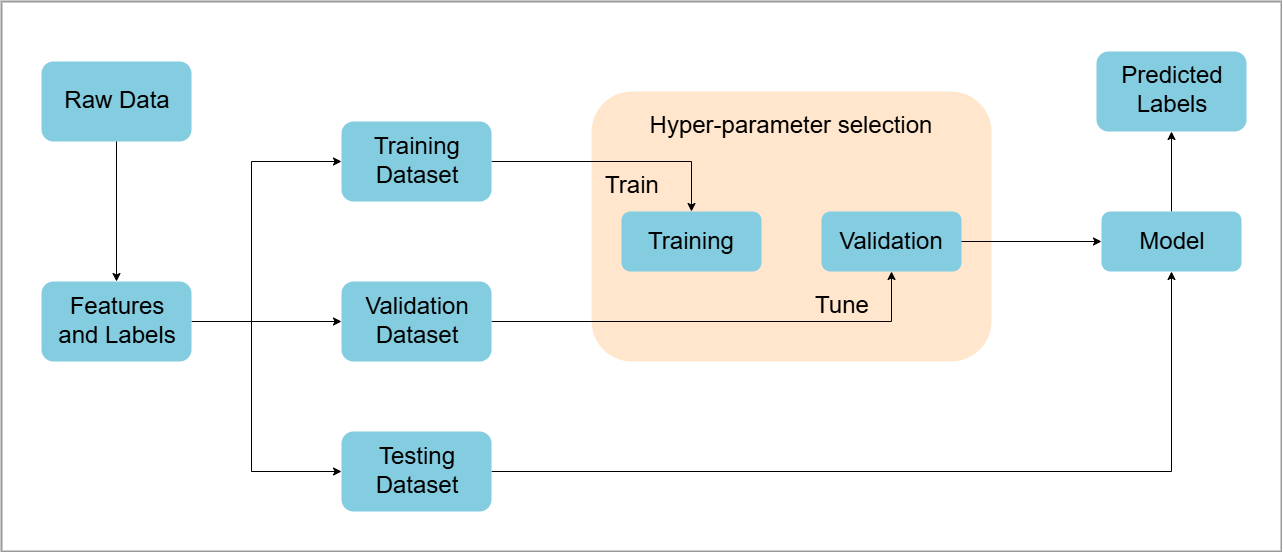
The workflow starts with raw data, which is processed into features and labels.
-
Dataset preparation
- Data is split into training, validation, and testing sets.
- Each set serves a specific role in model development.
-
Model training & tuning
- Training and validation sets refine the model.
- Hyperparameters are adjusted for better accuracy.
-
Final evaluation
- The testing dataset checks model performance.
- The trained model predicts labels based on new data.
The process results in a trained model capable of generating predicted labels.
Sample Scenario

New York City provides monthly apartment sales data, including square footage, neighborhood, year built, and sale price. The goal is to predict future sale prices, which makes this a supervised learning problem.
Step 1: Extract Features
- Reformat data to highlight useful details.
- Select key features like square footage and neighborhood.
Step 2: Split Dataset
- Divide data into training and testing sets.
- Use separate datasets for training and evaluation.
Step 3: Train Model
- Feed training data into a machine learning model.
- Choose a model like neural networks or regression.
Step 4: Evaluate
- Test the model on unseen data.
- Assess performance using metrics like accuracy or error rate.
- If results are good, deploy the model.
- Otherwise, adjust features or settings and retrain.
The Complete ML Workflow
A clear workflow consists of steps that build on each other, taking the process from data collection to deploying a reliable model.
- Requirements Gathering
- Data Preparation
- Model Development
- Model Evaluation and Tuning
- Model Testing
- Model Deployment