Improving Performance
Overview
After evaluating a model, we decide if its performance is sufficient. If not, we can improve the model using several methods:
- Dimensionality reduction
- Hyperparameter tuning
- Ensemble methods.
Dimensionality Reduction
A dimension denotes the number of features in your data. Dimensionality Reduction then refers to reducing the number of features in your data.
- May sound counterintuitive, since the more features we have, the more information.
- We just need to remove irrelevant features.
For example, predicting commute time:
- time of day is relevant
- weather is relevant
- number of glasses of water drank is not relevant
Some features might be highly correlated and carry similar information. For example, height and shoe size are correlated.
- Tall people most likely have large shoe sizes.
- We can keep height without losing much information.
We can also collapse multiple features into one underlying feature. For example, using Body Mass Index instead of height and weight separately.
Hyperparameter Tuning
Hyperparameter Tuning is like a music production console with settings for different genres. The dataset is the genre, and hyperparameters are the settings.
- We can tune the hyperparameter to come up with the better output.
- Depending on dataset, different hyperparameter values will give better or worse results
Recall the Support Vector Machine from Supervised Learning. We'll switching from a straight line to a curved one by changing the hyperparameter:
kernel = linear to polynomial.
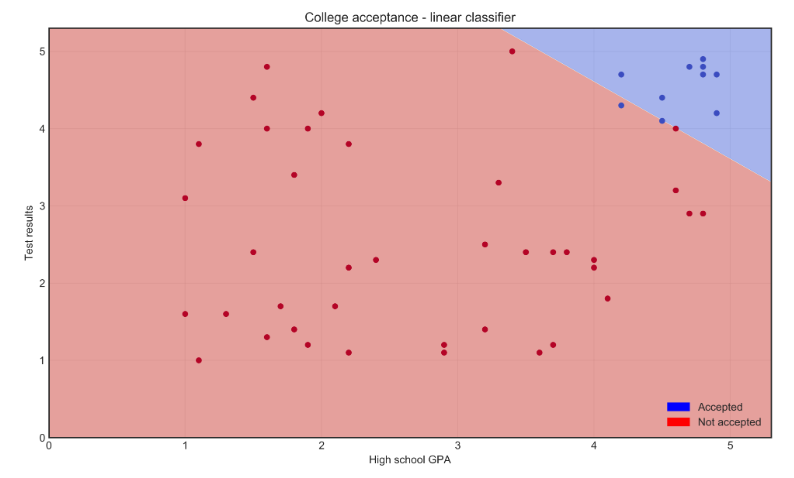
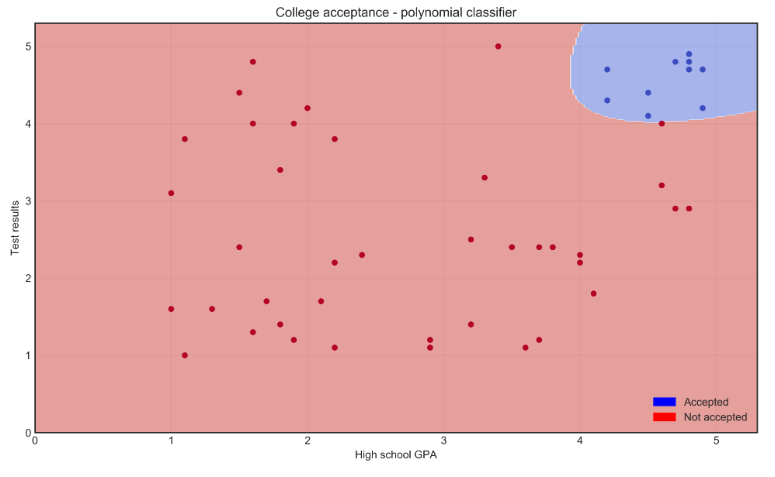
Tuning various hyperparameters impacts model performance.
Cdegreegammashrinkingcoef0
Ensemble Methods
Ensemble Methods refers to combining several models to produce one optimal model.
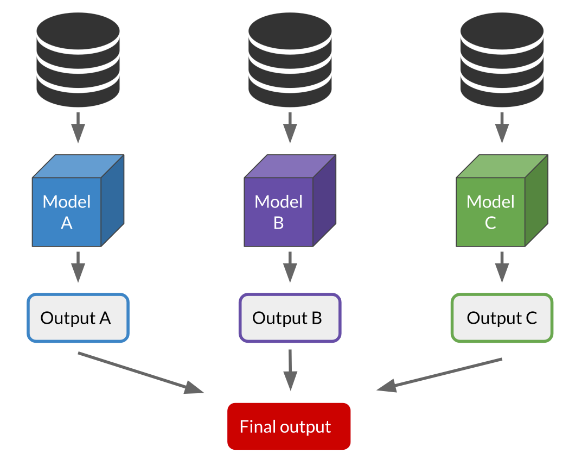
Example:
- Use the most common prediction from an SVM, K-means, and a Decision Tree model to assign a category to an observation.
- Use the average prediction from a Linear regression, a K-Means, and a Decision Tree model to assign a category to an observation.
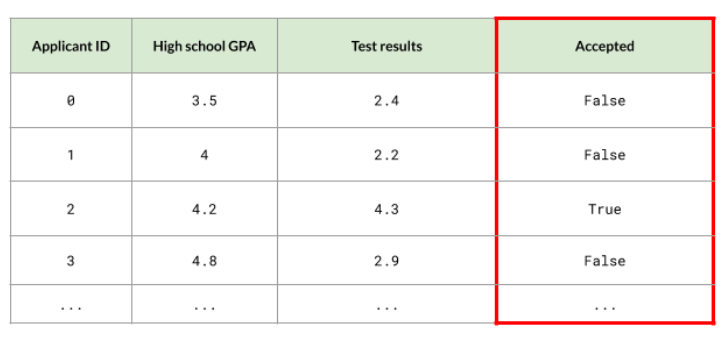
Case Study: College Admissions
We can use the college admissions case study where we have GPA and admission test results as the features, and we want to predict the number of students that will be aceepted. In a classification setting, we can use voting. If Model A and C accept a student, and Model B rejects, the student is accepted based on the majority vote.
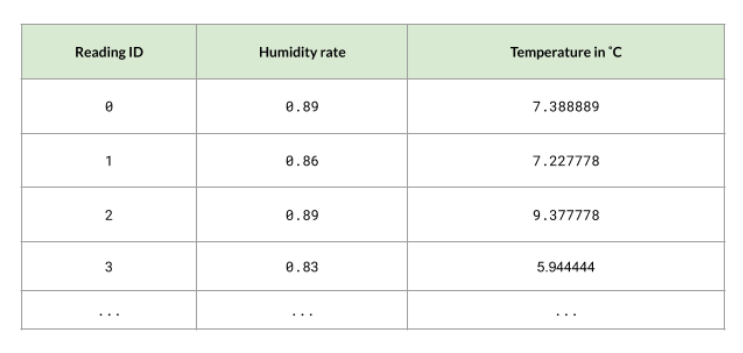
Case Study: Weather Temperatures
Another case study is predicting weather temperatures. We have the following data but we don't a specific set of labels, instead we have variable temperatures. In a regression setting. we can use averaging. If Model A predicts a temperature of 5, Model B predicts 8, and Model C predicts 4, the observation gets the average value, 5.67 degrees.