Unsupervised Learning
Updated May 04, 2023 ·
Overview
Unsupervised learning finds patterns in data without needing a target column. It helps uncover structure, relationships, or anomalies in datasets.
- Learns patterns from data automatically
- Clustering, anomaly detection, and association.
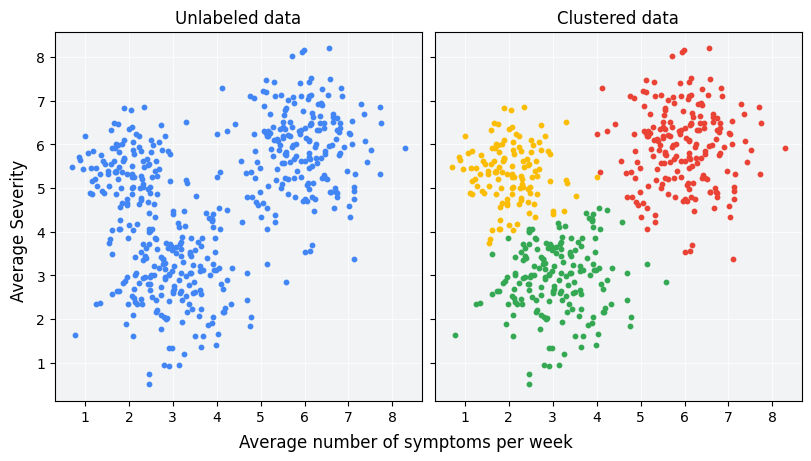
Clustering
Clustering groups similar observations together, making it easier to understand patterns or segments in the data.
- Animals grouped by breed or color
- Customer segments based on behavior
Below are some examples of clustering models:
-
K-Means
- Number of clusters must be defined in advance
- Groups points based on similarity or distance
- Useful for organizing or segmenting data
-
DBSCAN
- Density-based clustering that can handle noise
- Defines clusters based on point density
- No need to specify number of clusters
- Requires setting criteria for what counts as a cluster
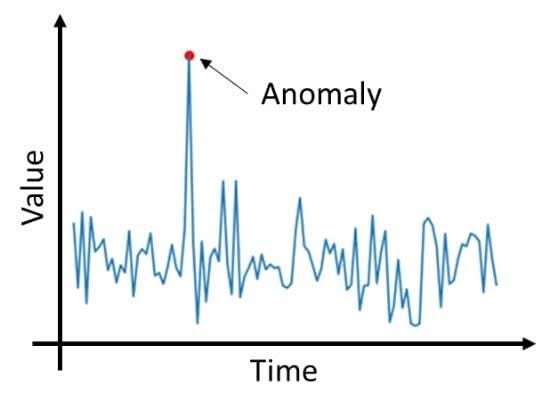
Anomaly Detection
Anomaly detection focuses on identifying outliers, which are observations that significantly differ from others.
-
Detecting Outliers
- Highlights unusual patterns or errors that may need attention
- Example: A data point far from a cluster of normal values
-
Removing Outliers
- Easier in low-dimensional data, harder in high-dimensional data
- Algorithms help identify complex anomalies
-
Use Cases
- Fraud detection
- Faulty device identification
- Error spotting
- Unusual medical cases
Association
Association involves finding relationships between observations, often used in market basket analysis to determine which items are bought together.
- Finding events that happen together.
- Helps discover hidden relationships in data
It is commonly used in market basket analysis to find patterns in what items are purchased together.
- Jam is often bought with bread, beer with peanuts, wine with cheese
- Helps retailers plan product placement
- Reveals hidden product patterns