Types of Machine Learning
Overview
Machine learning (ML) has three main types: reinforcement learning, supervised learning, and unsupervised learning. Each type differs in how it uses data to learn patterns.
- Reinforcement Learning: Learns by taking sequential actions; not covered here
- Supervised Learning: Uses labeled data to make predictions
- Unsupervised Learning: Uses unlabeled data to find patterns
These types allow computers to learn and make decisions in different ways, depending on the problem and data available.
Training Data
Training data is the foundation of machine learning. Models learn patterns from existing data and apply them to new inputs.
- Can be small or large; training time varies
- Includes features (input variables) and sometimes labels (output)
- Enables models to generalize to unseen dat
Supervised Learning
Supervised learning uses labeled data, where the correct outcome is known. It’s ideal for prediction problems like diagnosing diseases or predicting customer behavior.
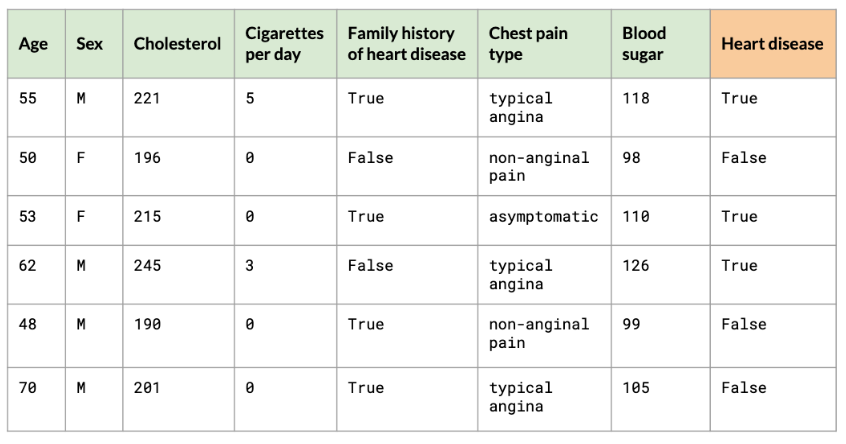
Where:
- Target Variable: The outcome to predict (e.g., heart disease)
- Labels: True/False or class values for the target
- Observations: Rows of data, also called examples
- Features: Columns of data that help predict the target (e.g., age, cholesterol)
With machine learning, we can analyze many features at once, even the ones we're unsure about, and find relationships between different features. Once the model is trained, new input data (like a new patient) is provided, and the model predicts the outcome.
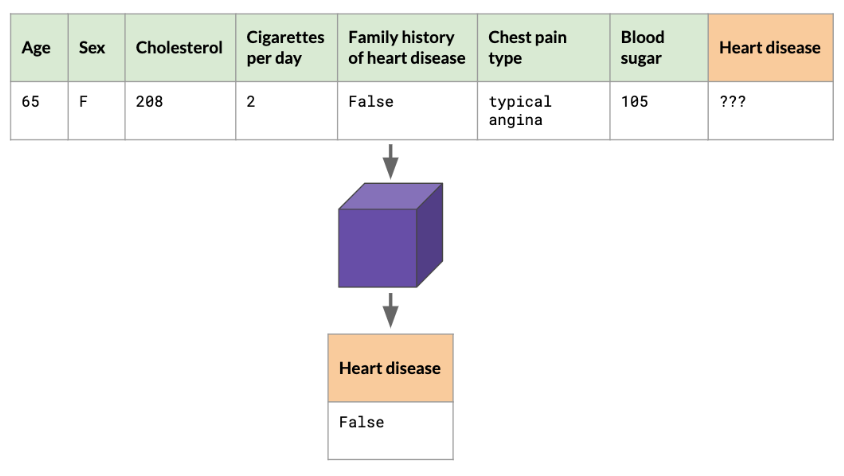
Unsupervised Learning
Unsupervised learning uses data without labels. It finds patterns or groups within the data. This is useful for clustering, anomaly detection, or discovering hidden relationships.
- Clustering: Groups similar observations together
- Anomaly Detection: Identifies unusual data points
- Feature-based Analysis: Discovers patterns without predefined labels
Example: Grouping heart disease patients by age, cholesterol, and blood sugar to identify patient types.
When a new patient’s data is provided, the model assigns them to the most similar group. This helps with research, treatment planning, and understanding data patterns.
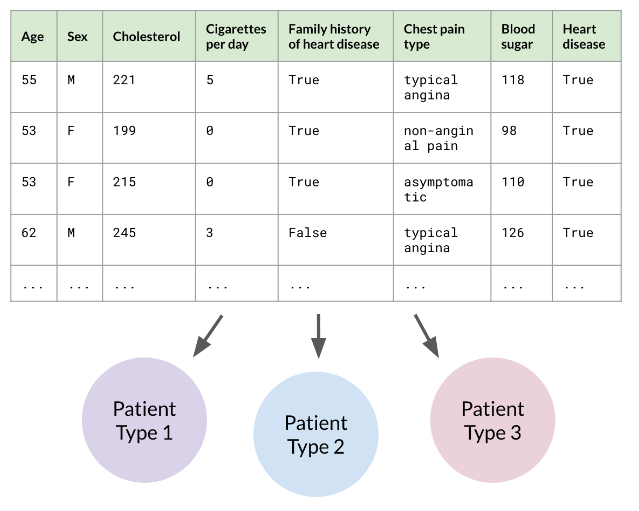
Often, data doesn’t have labels because labeling is too time-consuming or unclear, like labeling millions of road images for self-driving cars. Unsupervised learning excels in these situations, discovering patterns automatically without supervision.